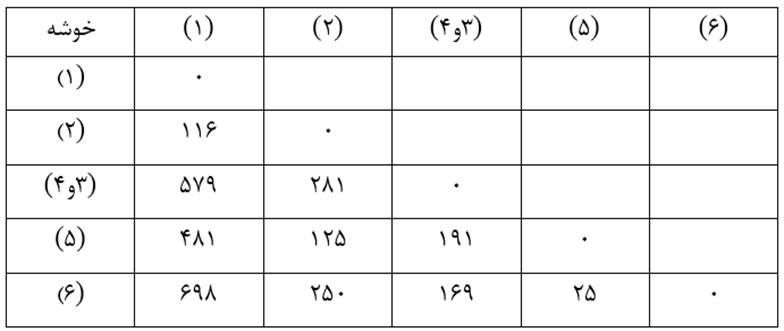
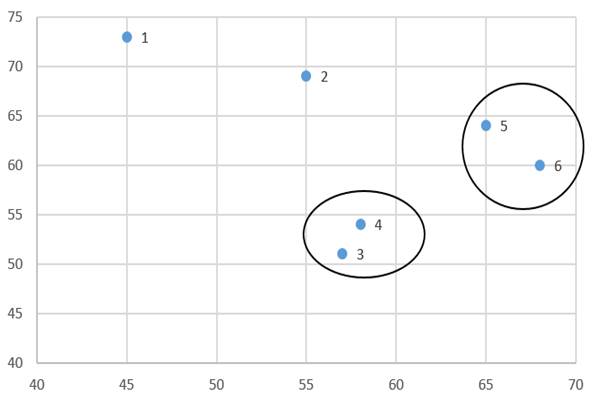
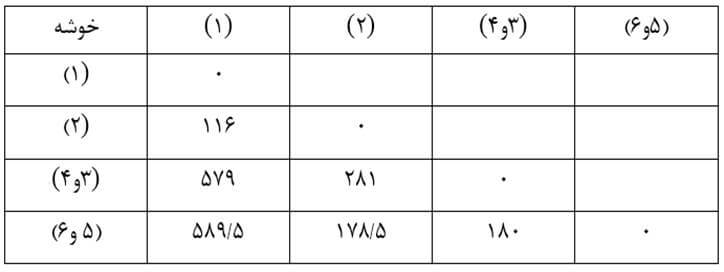
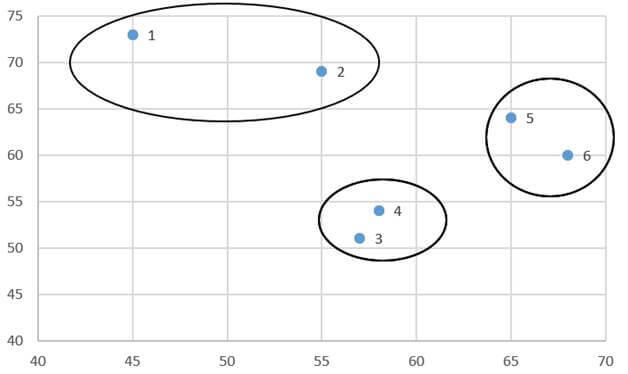
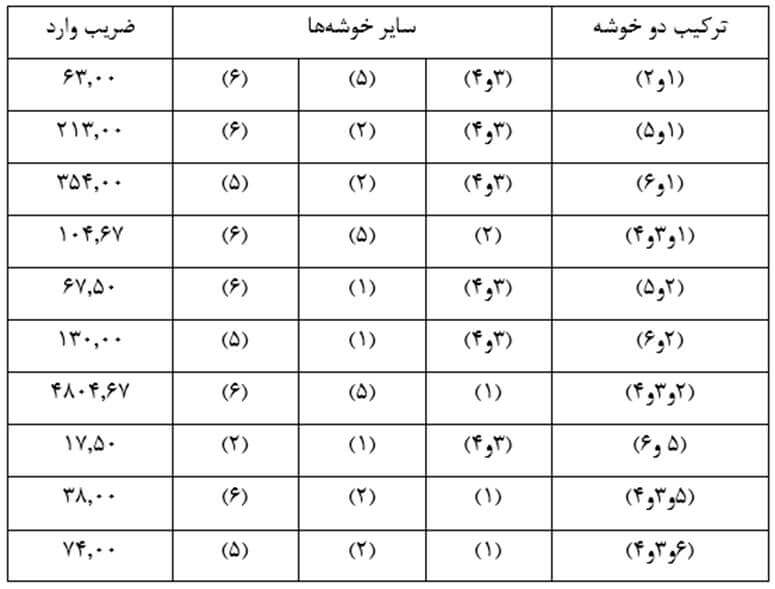
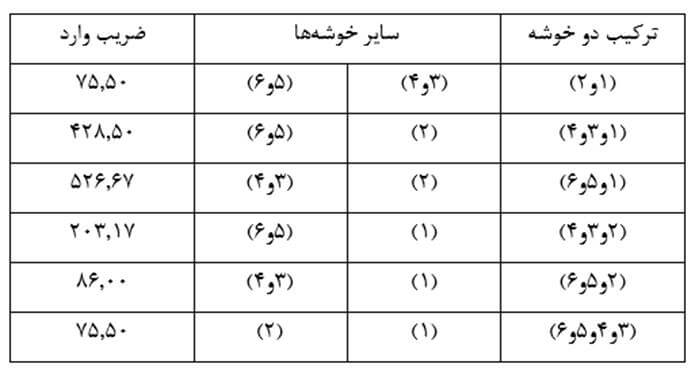
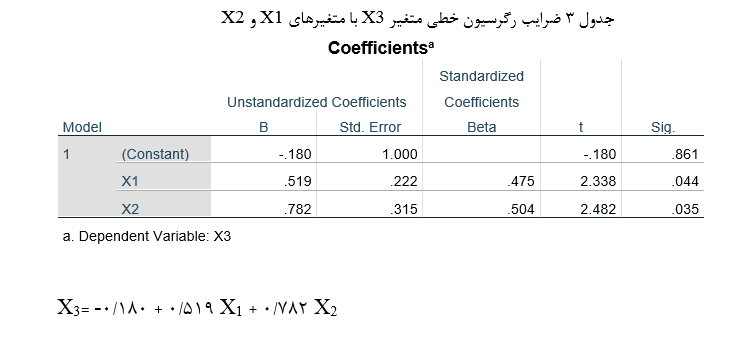
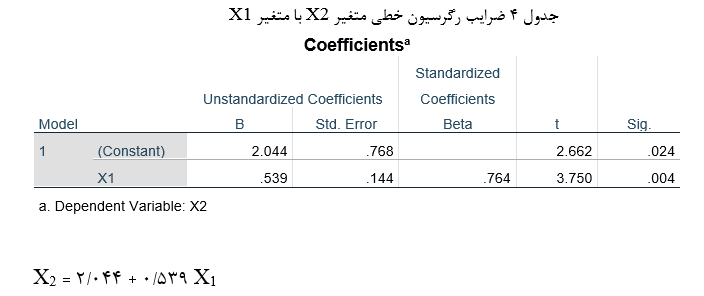
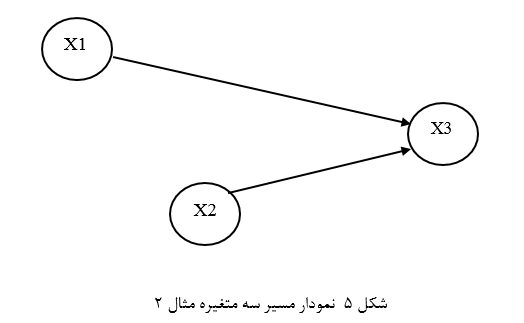
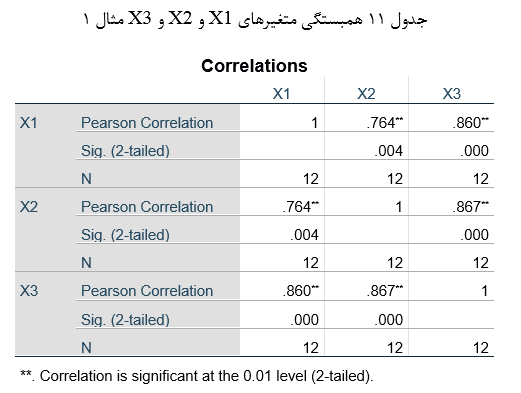
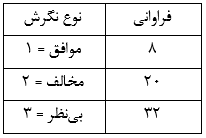
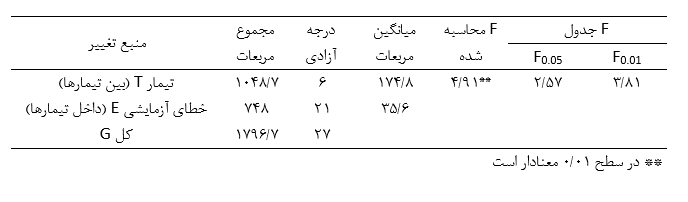
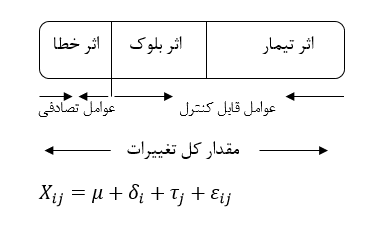
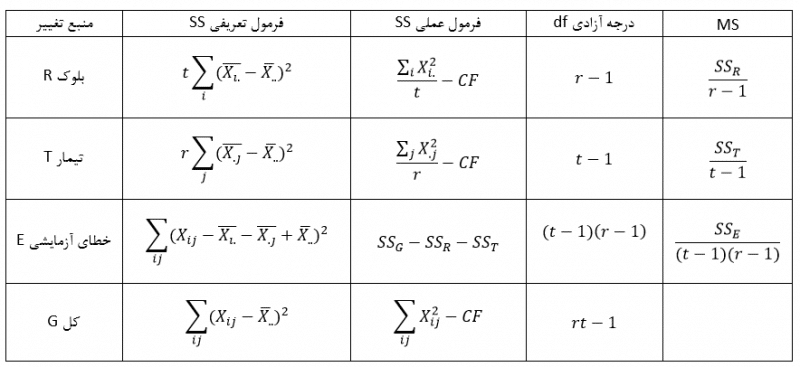
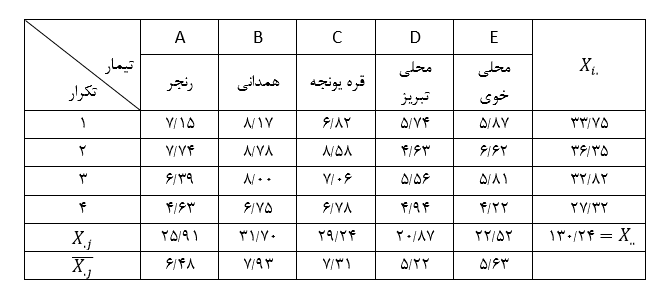
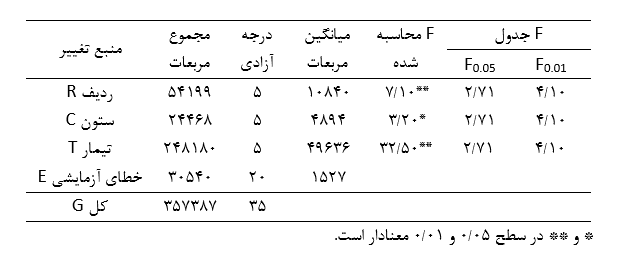
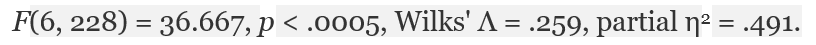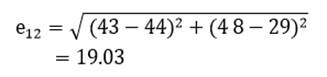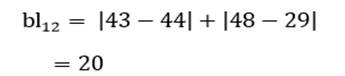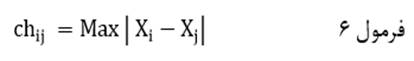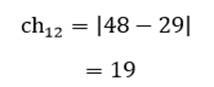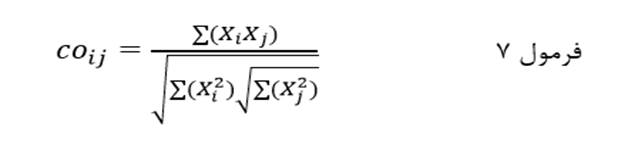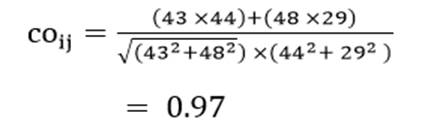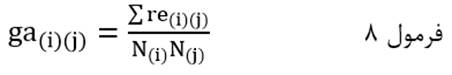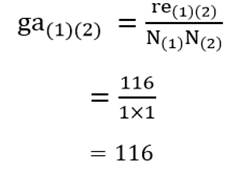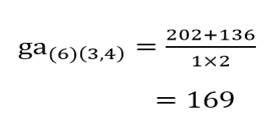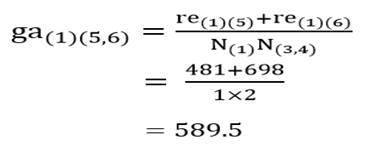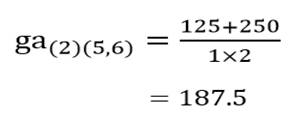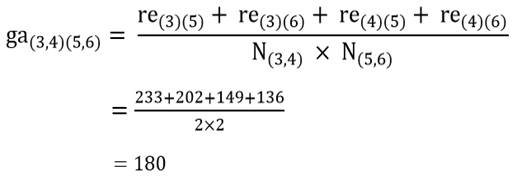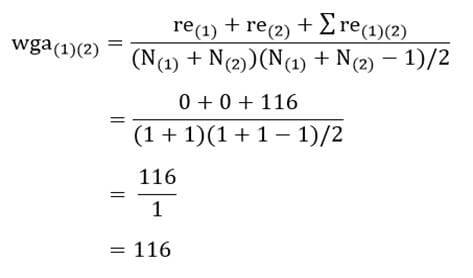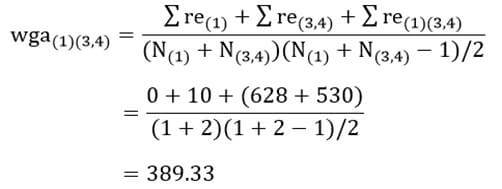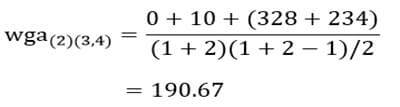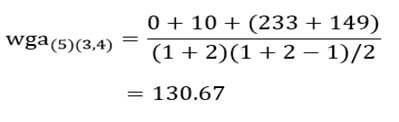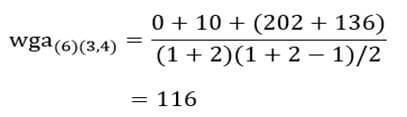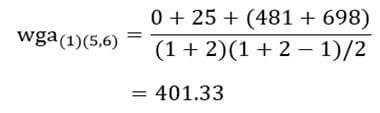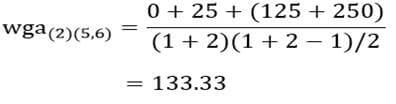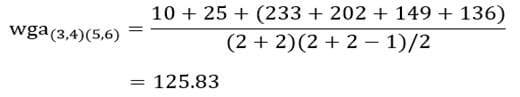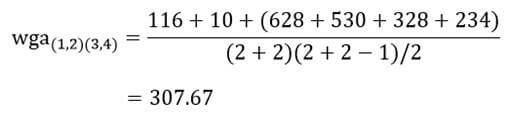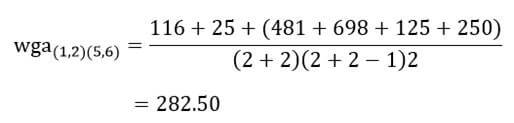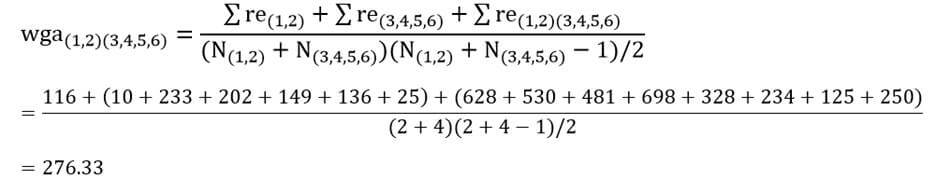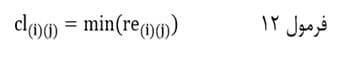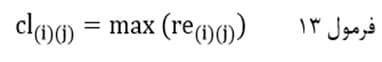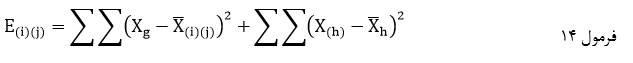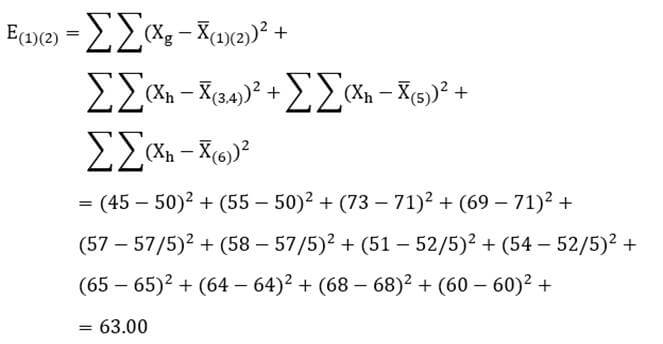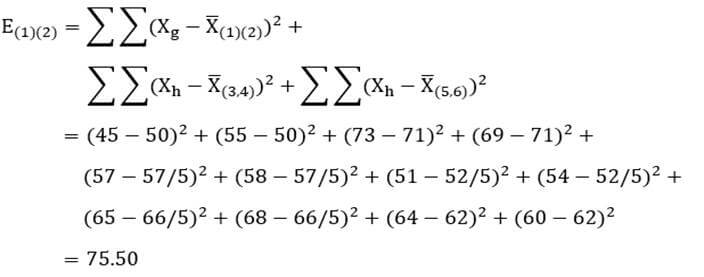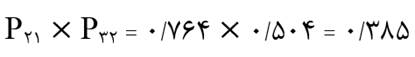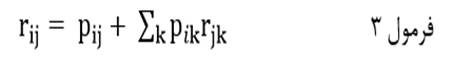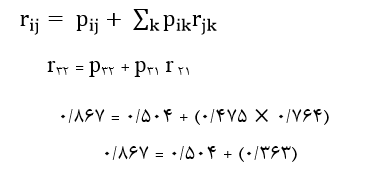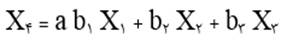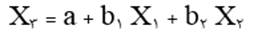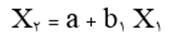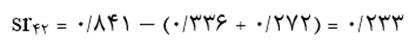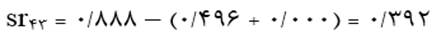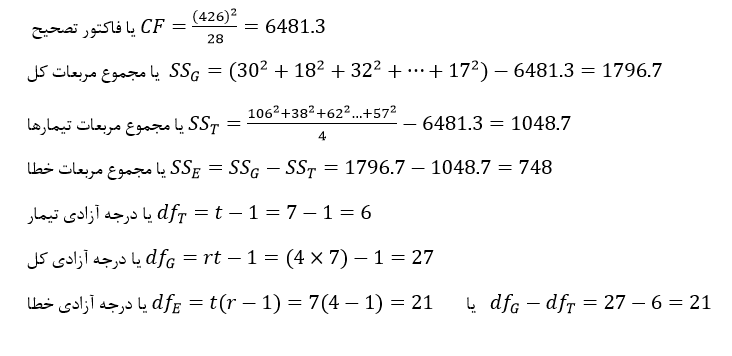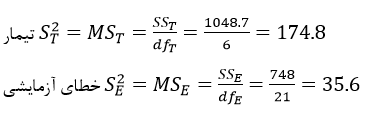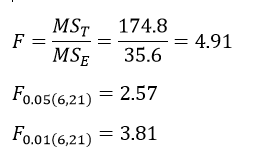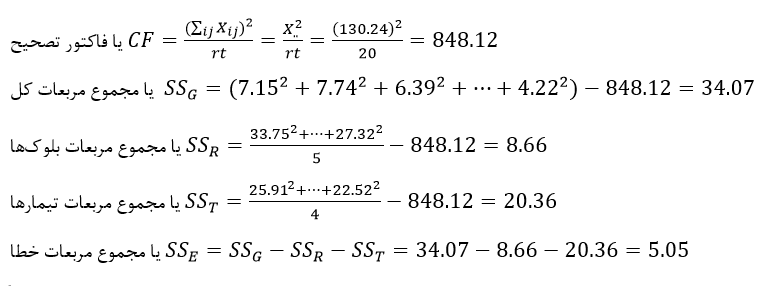آزمون نرمال بودن داده ها پیش نیاز بسیاری از آزمون های آماری است زیرا نرمال بودن داده ها یک فرض زیربنایی در آزمایش های پارامتری است. نرمال بودن داده ها جز یکی از اصلی ترین آزمون هایی است که باید برای استفاده از هر داده از آن استفاده کنیم.
دو روش اصلی ارزیابی نرمال بودن وجود دارد: از نظر گرافیکی و عددی و یا از نظر آزمون های آماری. زمانی که می گوییم از نظر گرافیکی نرمال بودن داده ها را بررسی کنید، به این معنی است که می خواهیم با استفاده از نمودارها و شاخصهای آماری مانند نمودار q-q plot و یا چولگی و کشیدگی و … نرمال بودن دادهها را بررسی کنید. زمانی که می خواهیم با استفاده از آزمون های آماری نرمال بودن داده ها را بررسی کنیم، به این معنی است که با استفاده از آزمون هایی مانند کلوموگروف-اسمیرنوف یا شاپیرو ویلک و … نرمال بودن دادهها را بررسی کنیم. پیشنهاد اکثر متخصصین آمار، استفاده از هر دو مسیر برای بررسی نرمال بودن دادههاست.
این بخش به شما کمک خواهد کرد تا مشخص کنید که آیا داده های شما نرمال هستند یا خیر. رویکردها را می توان به دو موضوع اصلی تقسیم کرد: تکیه بر آزمون های فرضیه ای یا نمودار های آماری.
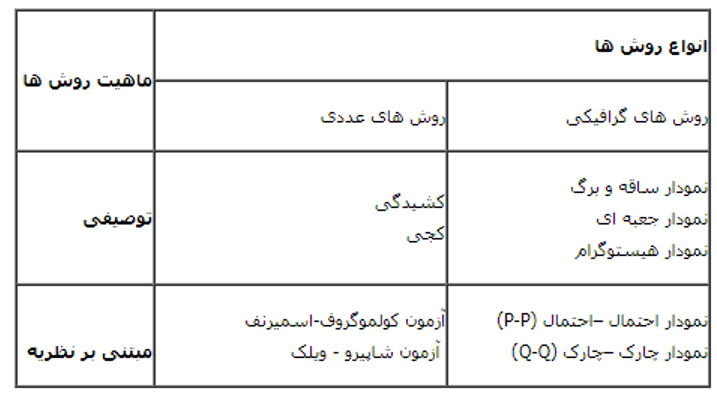
آزمون های فرضیه ای این مزیت را دارند که قضاوت عینی در مورد نرمال بودن انجام دهند، اما گاهی اوقات دقت لازم برای حجم نمونه های کوچک ندارد و یا بلعکس حساسیت زیادی برای حجم نمونه های بزرگ دارد. به این ترتیب، برخی از آماردانان ترجیح می دهند برای برسی نرمال بودن داده ها از پلات ها/گراف ها استفاده کنند.
تفسیر گرافیکی این مزیت را دارد که برای آزمون های آماری دارای حساسیت بالا یا کم تر از حد معمول یک قضاوت خوب ارائه دهد، اما روش های گرافیکی فاقد عینیت هستند. اگر تجربه زیادی در تفسیر نرمال بودن به صورت گرافیکی نداريد، بهتر است به روش های عددی تکيه کنيد.
در قسمت های قبلی به بررسی آزمون کولموگروف اسمیرنوف پرداختیم. در این قسمت ما در ابتدا به آموزش بررسی نرمال بودن داده ها با استفاده از آزمون شاپیرو ولیک و نمودار q-q پلات در نرم افزار spssمی پردازیم و سپس با ارائه مثالی موضوع را روشن تر می کنیم.
آزمون نرمال بودن داده ها در SPSS
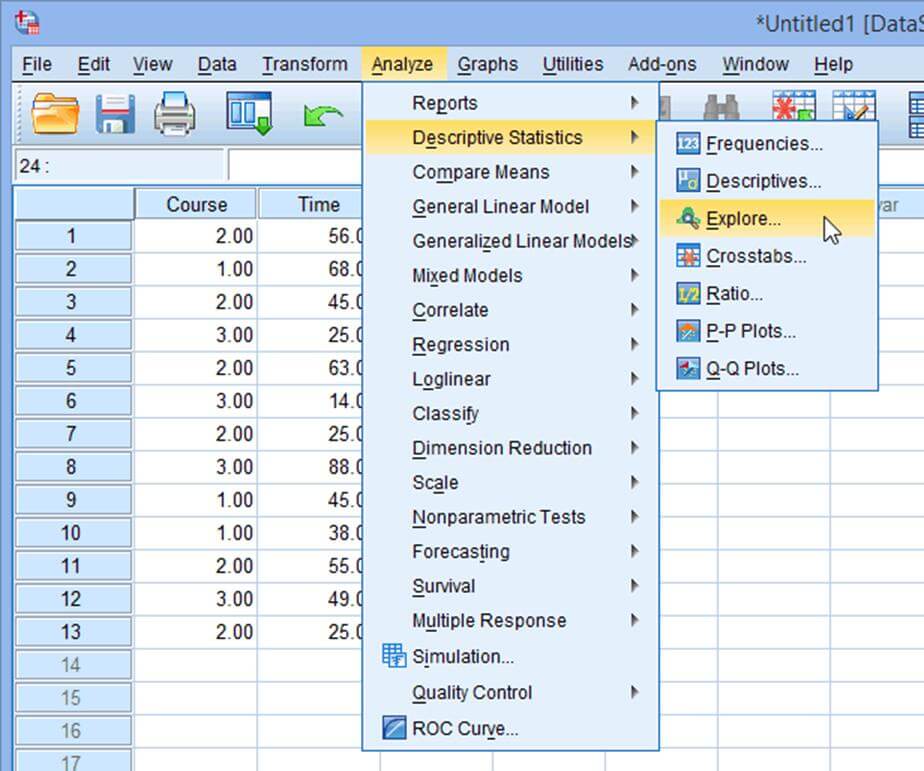
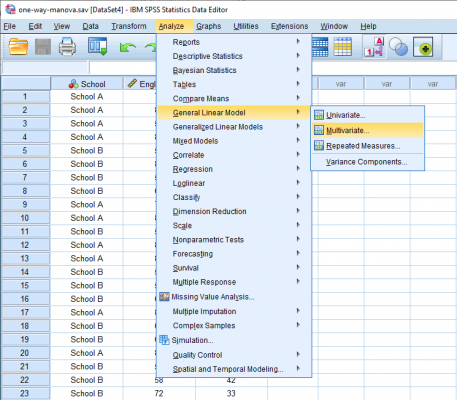
در نرم افزار spss با استفاده از دستور explor شما می توانید انتخاب کنید که نرمال بودن را برای یک گروه آزمون کنید یا آن ها را به چند گروه تقسیم کنید و سپس آزمون نرمال بودن را انجام دهید. به طور مثال اگر شما گروهی داشته باشید و بخواهید نرمال بودن قد آن ها را آزمون کنید با استفاده از دستور explore این کار را می توانید انجام دهید.
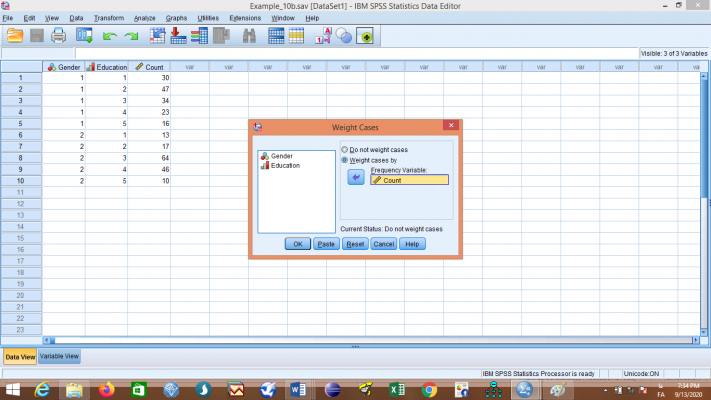
شما می توانید داده ها را به دو گروه مرد و زن تقسیم کنید و نرمال بودن را برای هر کدام از آن ها ازمون کنید. لازم به ذکر است که اگر تعداد گروه های ارزیابی شما دو یا بیشتر باشند باید از دستور split نیز استفاده نمایید و دستور explore به تنهایی کافی نیست.
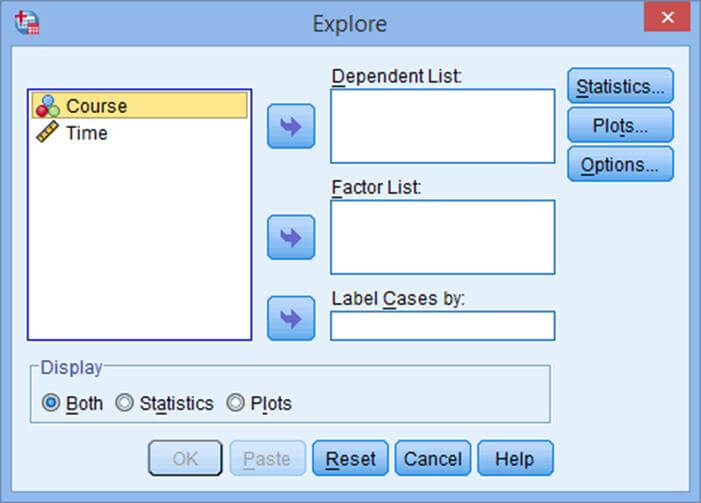
همانطور که در عکس زیر نمایش داده شده است کلیک نمایید:

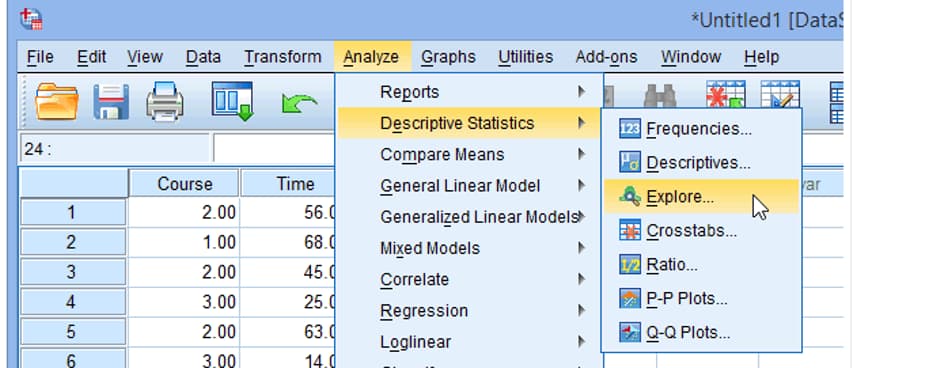
جعبه explore به صورت زیر برای شما نمایش داده می شود:
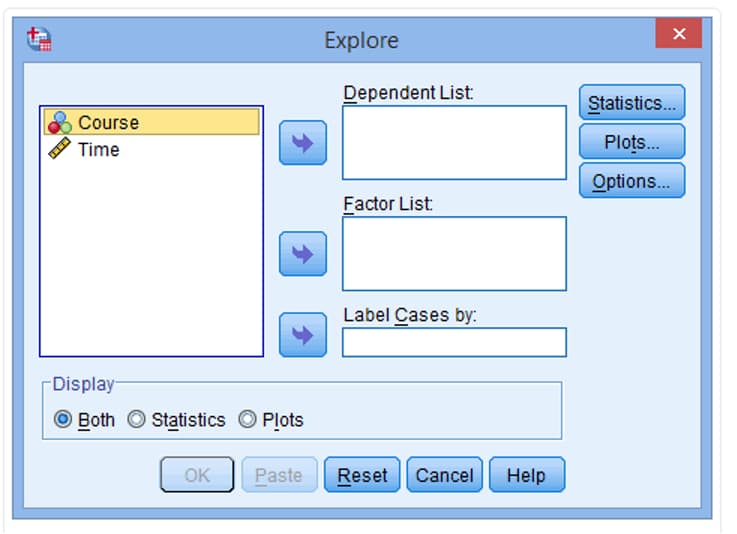
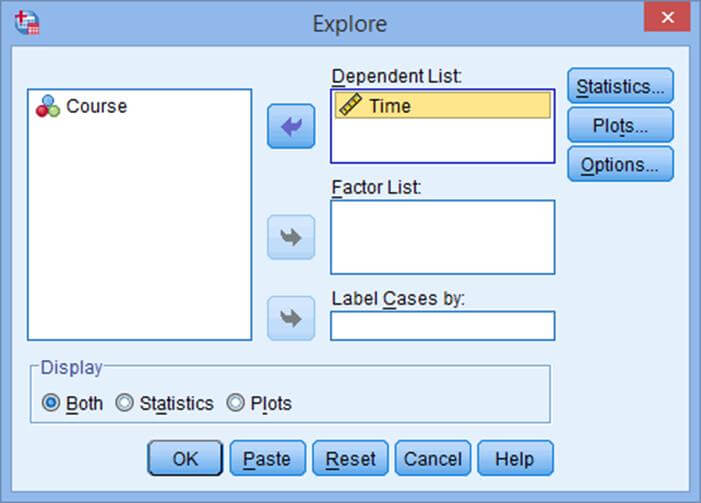
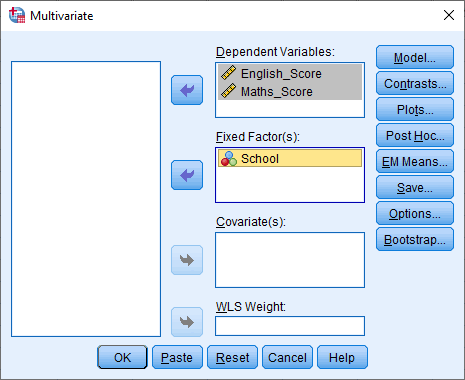
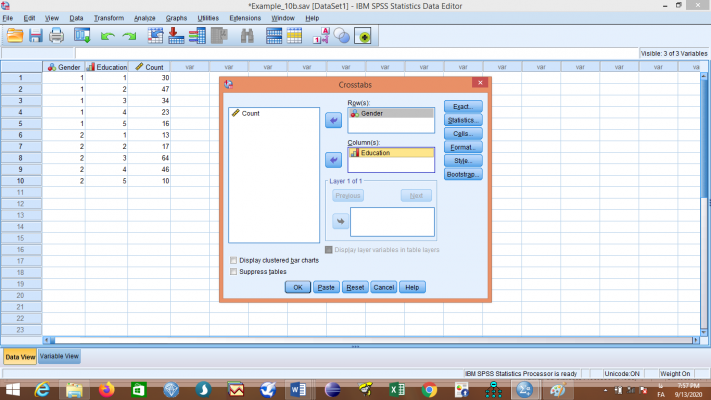
متغیری که نرمال بودن آن را می خواهید آزمون کنید را به بخش Dependent List منتقل نمایید.
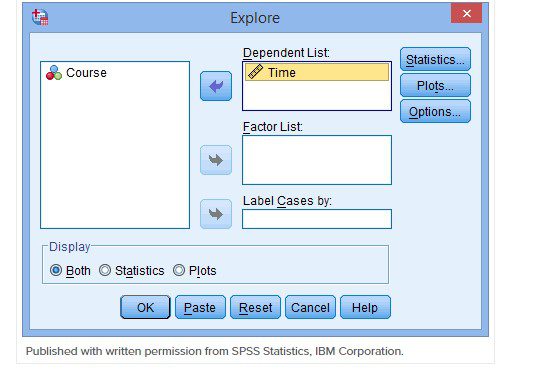
[اختیاری] اگر می خواهید بدانید متغیر شما برای هر سطح از متغیر مستقل به طور نرمال توزیع شده است، متغیر مستقل را به قسمت factor list منتقل کنید.
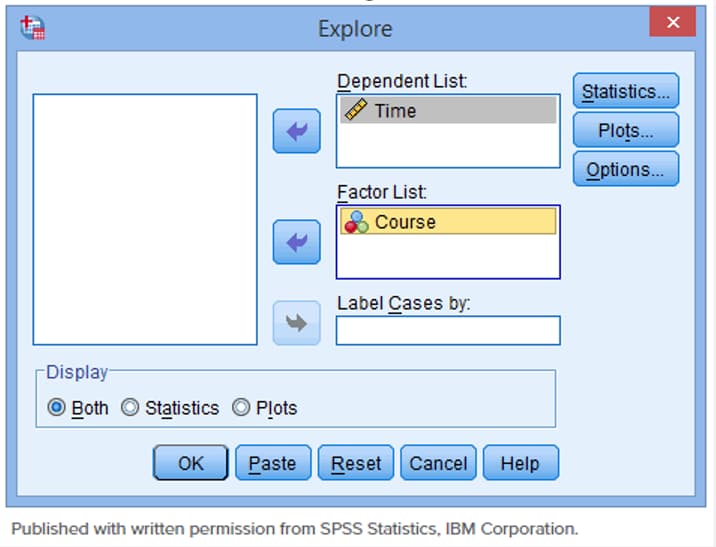
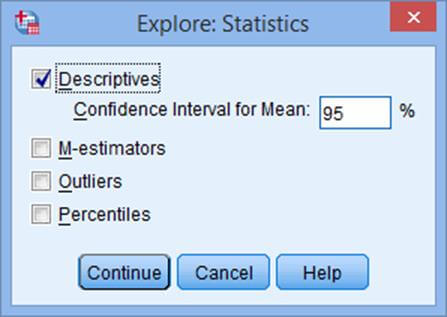
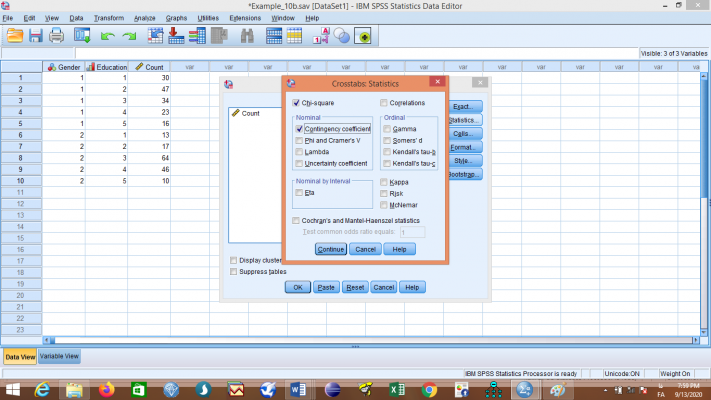
روی گزینه statistics در قسمت بالا کلیک نمایید و سپس
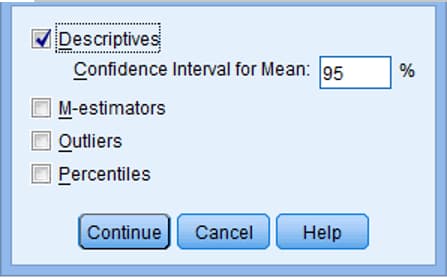
روی continue کلیک نمایید .
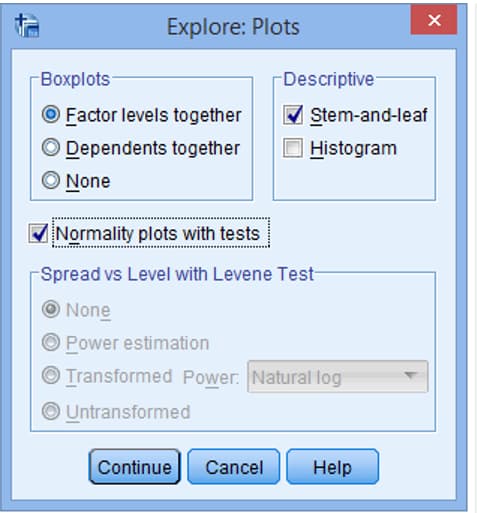
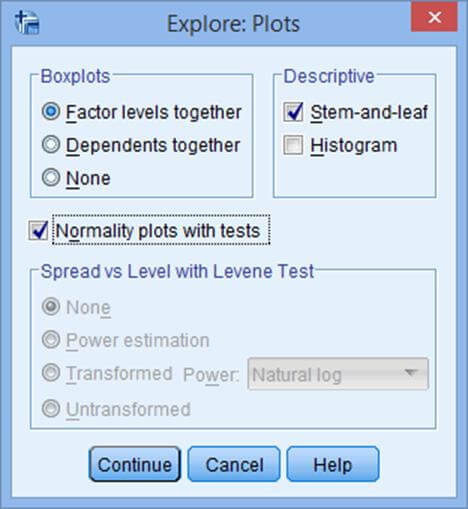
روی گزینه Plot کلیک نمایید
روی continue و سپس ok کلیک نمایید.
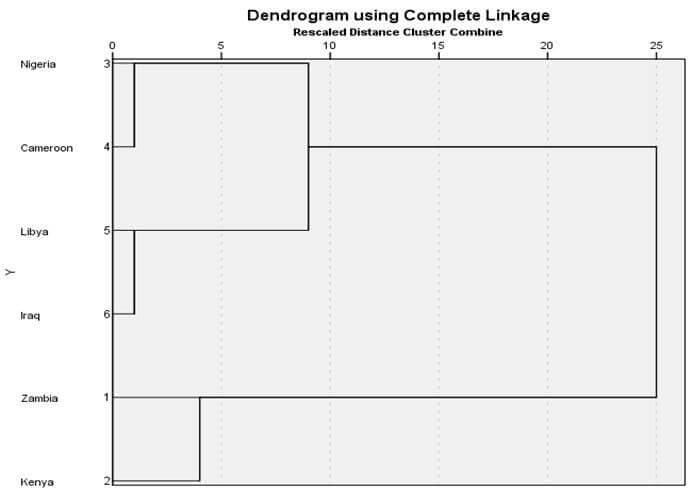
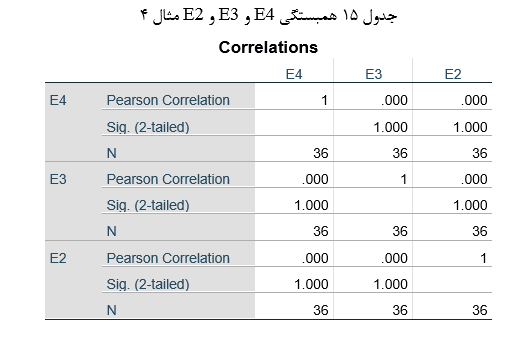
دز خروجی این آزمون جدول های مختلفی به نمایش در می آید که همه ی آنها برای بررسی نرمال بودن استفاده نمی شود. برای بررسی نرمال بودن، ما به جدول آزمون شاپیرو ویلک و نمودار q-q plot نیازمندیم.
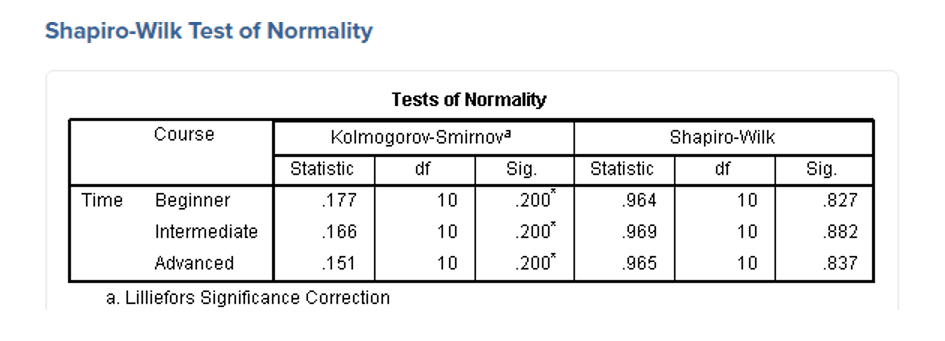
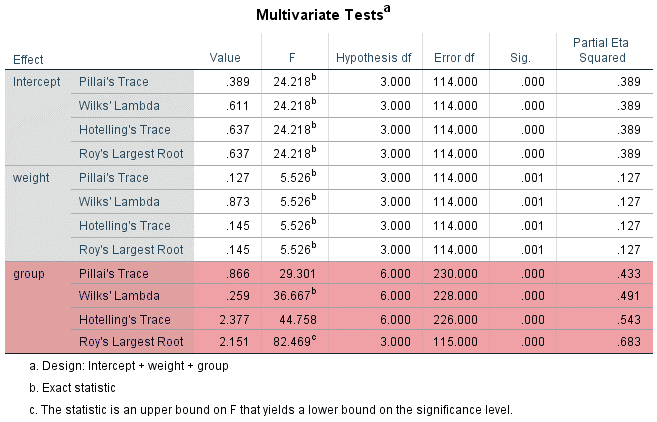
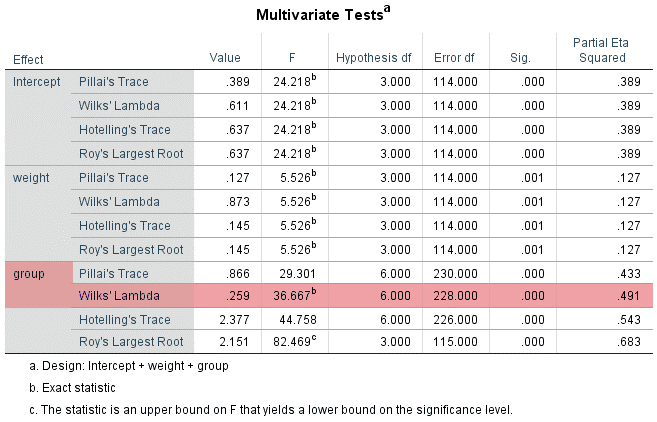
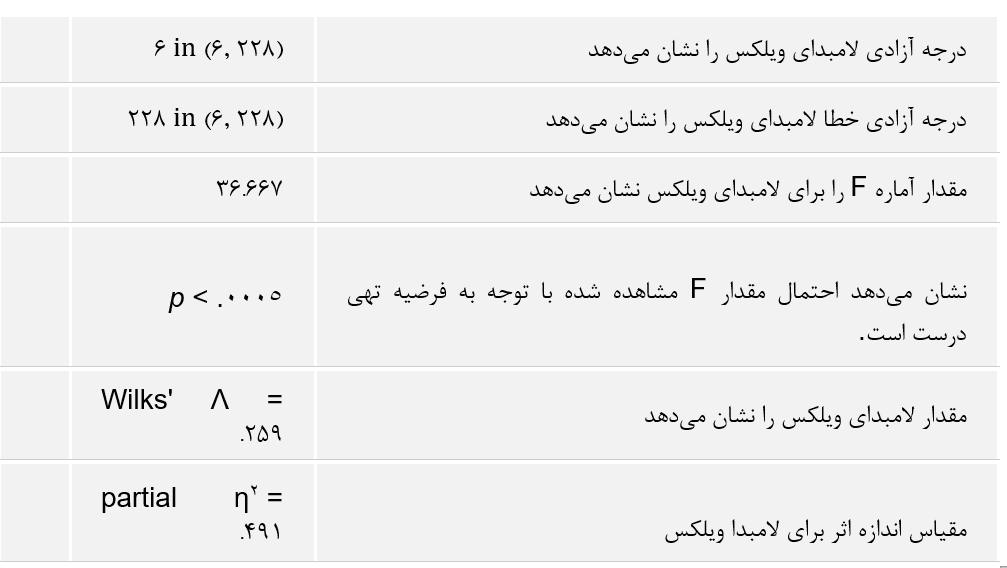
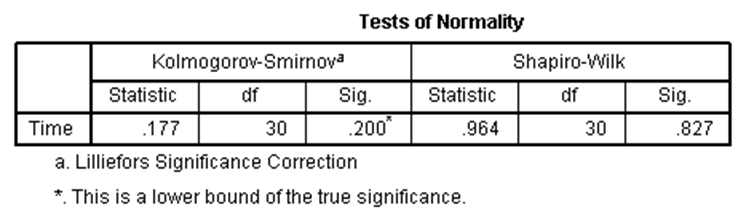
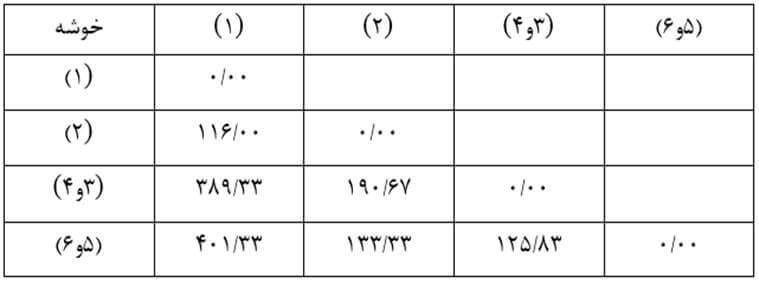
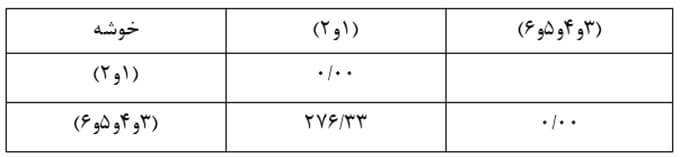
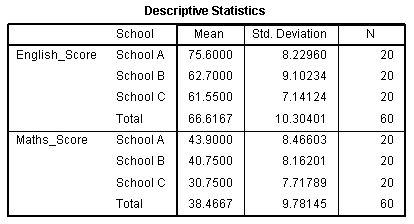
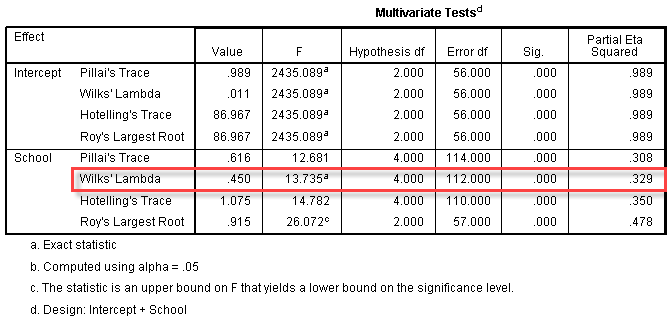
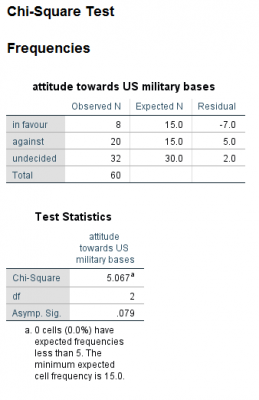
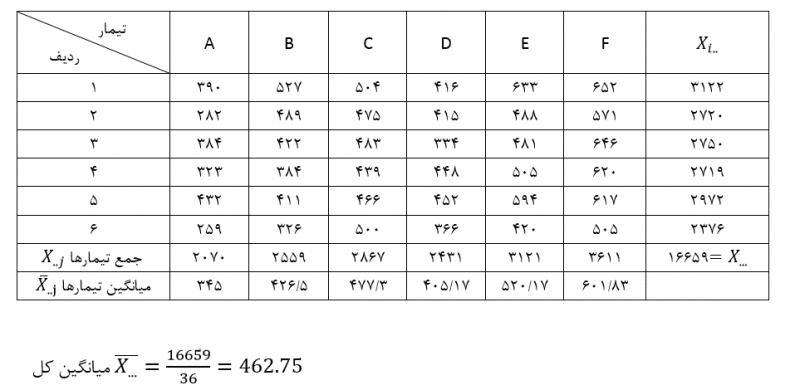
جدول بالا نتایج حاصل از دو آزمایش شناخته شده نرمال بودن یعنی آزمون کولموگوروف-اسمیرنوف و آزمون شاپیرو-ویلک را ارائه می دهد. آزمون شاپیرو-ویلک برای اندازه نمونه های کوچک (کمتر از ۵۰ نمونه) مناسب تر است، اما می تواند برای حجم نمونه تا 2000 نیز مورد استفاده قرار بگیرد. به همین دلیل، ما از آزمون شاپیرو-ویلک به عنوان آزمون عددی برای ارزیابی نرمال بودن داده ها استفاده خواهیم کرد.
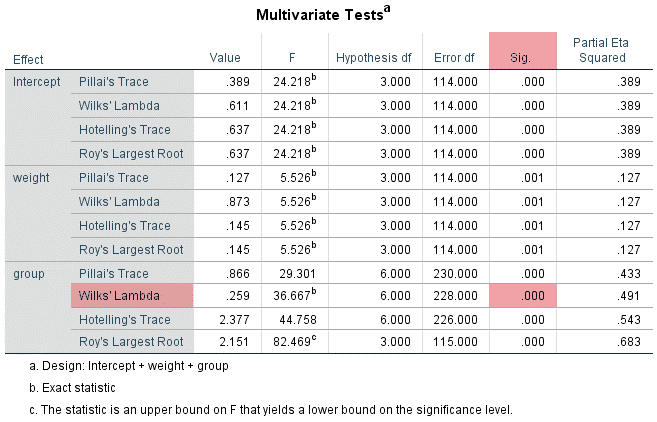
از جدول بالا می بینیم که برای گروه دوره های “مبتدی”، “متوسط” و “پیشرفته” متغیر وابسته، “زمان”، به طور نرمال توزیع شده است. راه تشخیص بدین گونه است که اگر مقدار sig آزمون شاپیرو-ویلک بیشتر از ۰٫۰۵ باشد، داده ها نرمال است. اگر زیر ۰٫۰۵ باشد، داده ها از یک توزیع نرمال پیروی نمی کنند.
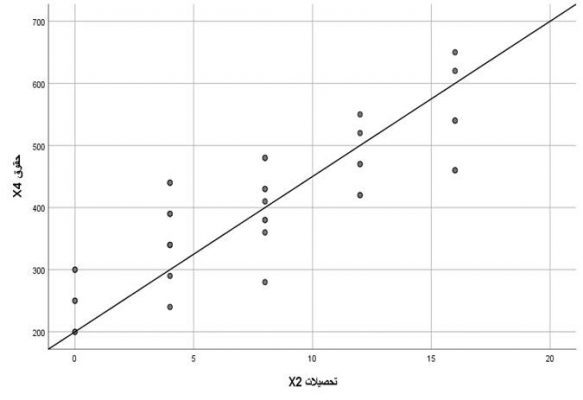
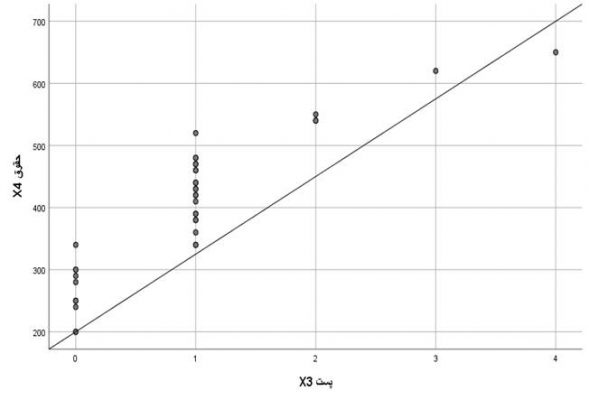
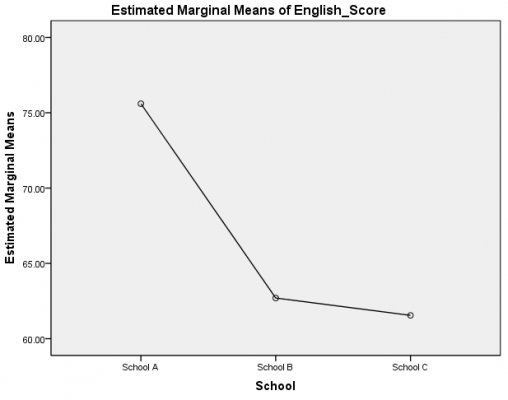
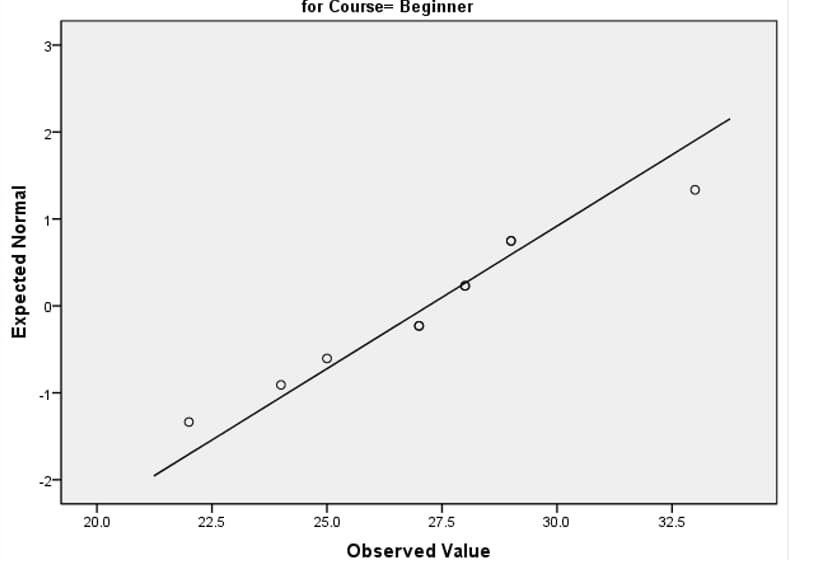
نمودار q-q plot در بررسی نرمال بودن داده ها
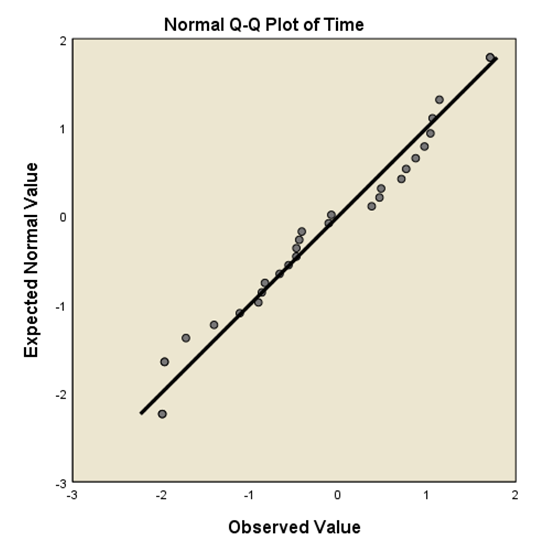
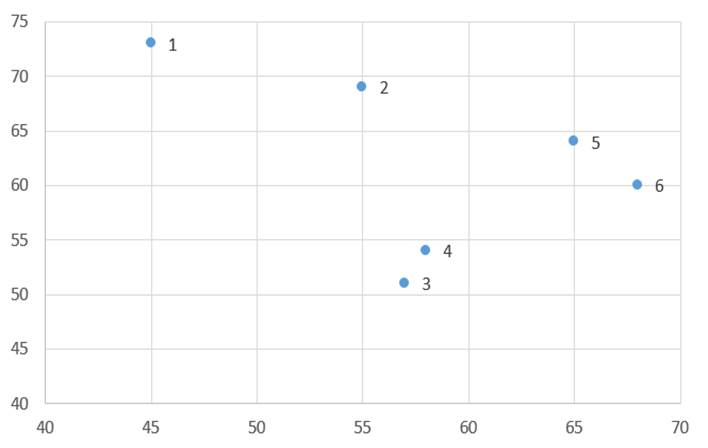
به منظور تعیین نرمال بودن داده ها به صورت گرافیکی، می توانیم از خروجی نمودار Q-Q استفاده کنیم. اگر داده ها به طور نرمال توزیع شوند، نقاط داده نزدیک به خط مورب خواهند بود. اگر داده ها روی خط مورب قرار نگرفته باشند، داده ها به طور نرمال توزیع نشده اند.
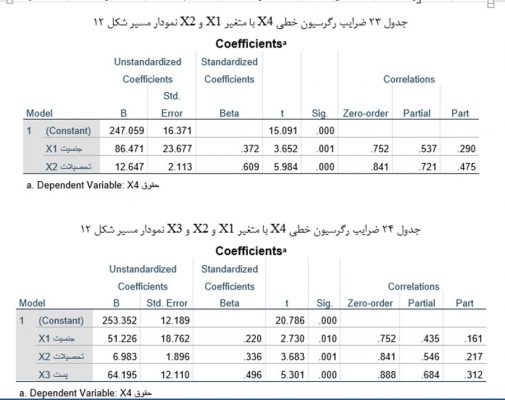
زمانی که دو یا چند متغیر مستقل وجود دارد برای بررسی نرمال بودن داده ها چه کنیم
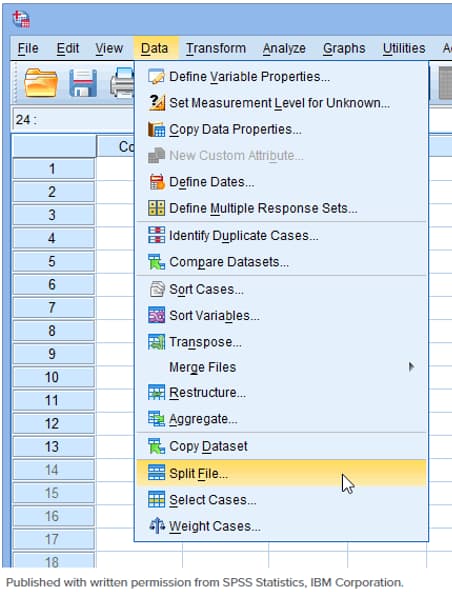
دستورexplore به تنهایی نمی تواند متغیر وابسته را به گروه های دو یا چند متغیر مستقل جدا کند. با این حال، ما می توانیم این کار را با استفاده از دستور split file انجام دهید.
همانطور که در زیر نشان داده شده است. روی split file> کلیک کنید.
سپس تصویر زیر برای شما به نمایش در می آید.
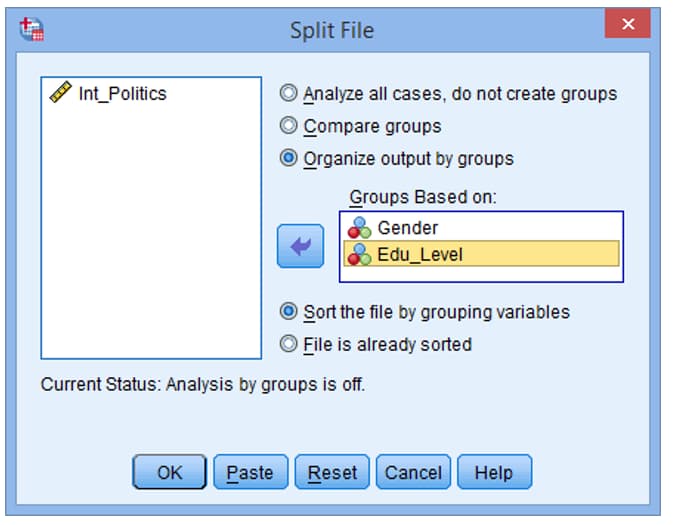
گزینه ok را انتخاب کنید.
توجه: پرونده شما اکنون اسپلیت شده است و خروجی از هر آزمونی با توجه به گروه هایی که انتخاب کرده اید انجام خواهد شد.
حال مسیر زیر را مطابق شکل انتخاب نمایید.
Analyze > Descriptive Statistics > Explore
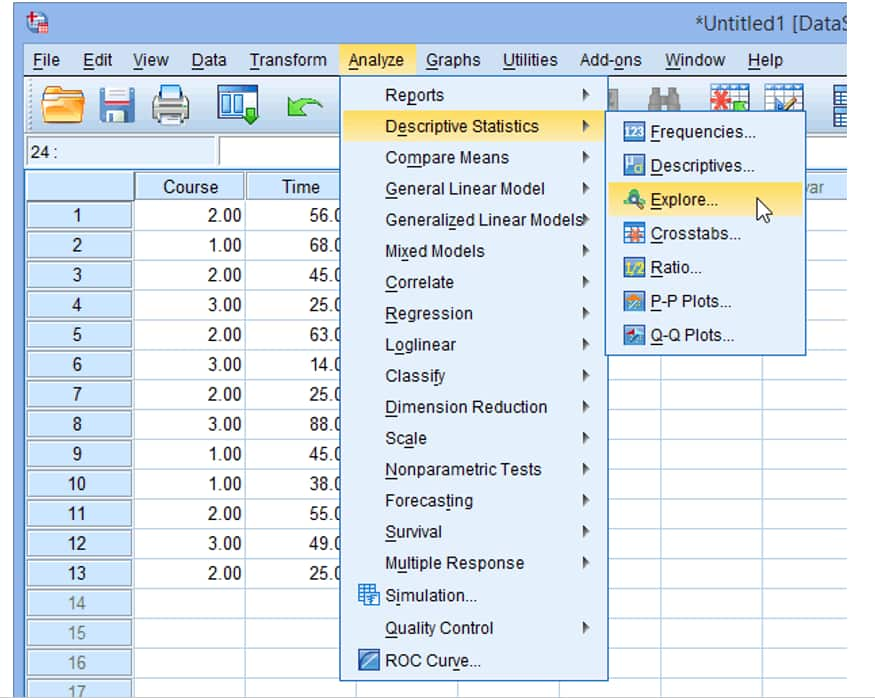
پنجره explore مطابق شکل زیر به نمایش در می آید:
گزینه های فوق را تغییرندهید و روی گزینه continue کلیک کنید.
متغیری را که باید برای نرمال بودن آزمون شود به Dependent List منتقل نمایید. در این مثال، متغیر Int_Politics را به Dependent List منتقل می کنیم. سپس برای شما صفحه نمایش زیر ارائه خواهد شد:
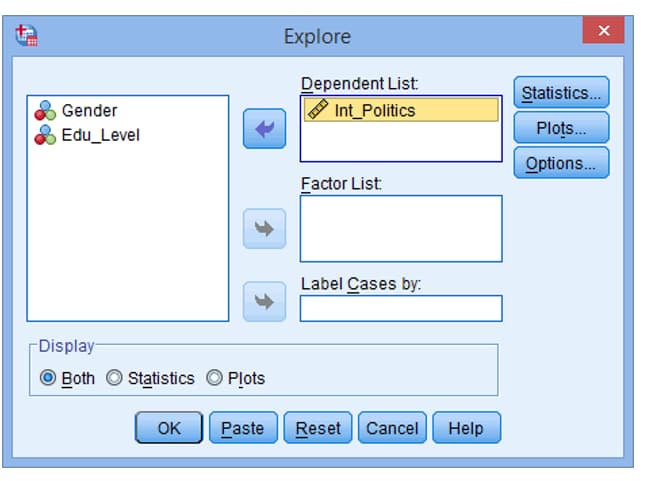
اکنون خواهید دید که خروجی بر اساس ترکیب گروه های دو متغیر مستقل به بخش های جداگانه تقسیم شده است. در این مثال آزمون های نرمال بودن را نشان می دهیم به طوری که متغیر وابسته، “Int_Politics”، در گروه اول “جنسیت” (مرد) و اولین گروه “Edu_Level” (School) دسته بندی می شود. تمام ترکیب های ممکن دیگر نیز در خروجی کامل ارائه شده است.

جدول آزمون نرمال بودن به صورت زیر به نمایش در می آید:

آزمون شاپیرو-ویلک در حال حاضر در حال تجزیه و تحلیل نرمال بودن “Int_Politics” بر روی داده های “مرد” در متغیر مستقل، “جنسیت”، و “مدرسه” در متغیر مستقل “Edu_Level” طبقه بندی شده است. همانطور که ارزش sig در زیر ستون شاپیرو-ویلک بیشتر از 0.05 است، می توانیم به این نتیجه برسیم که “Int_Politics” برای این زیرمجموعه خاص از افراد به طور نرمال توزیع شده است.
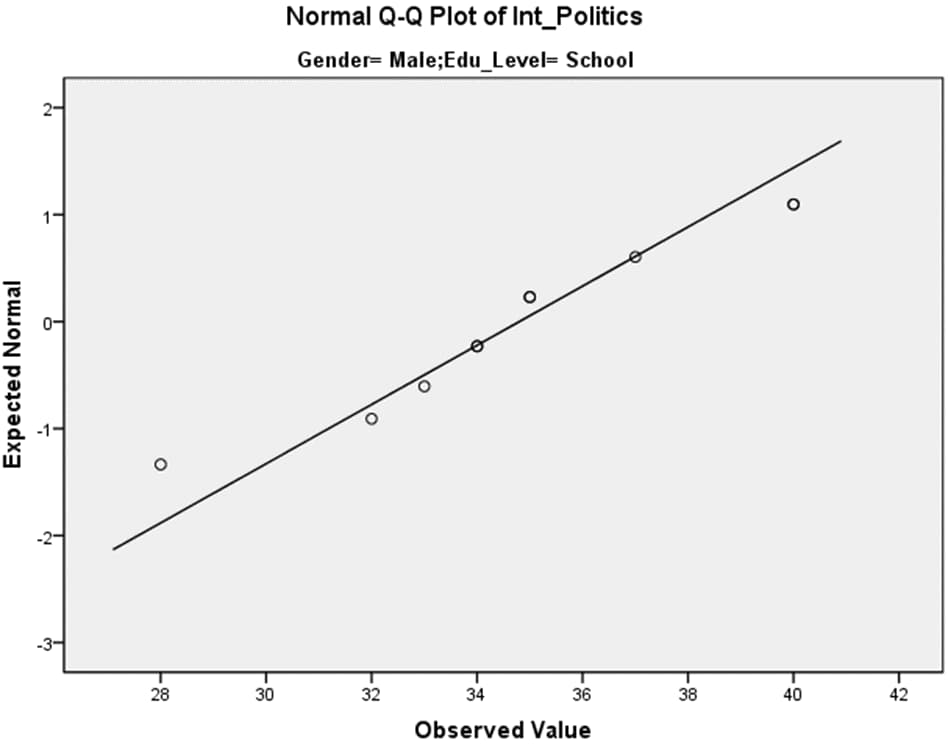
با استفاده از این داده ها به رسم نمودار Q-Qplot می پردازیم. از این گراف می توان نتیجه گرفت که به نظر می رسد داده ها به طور نرمال توزیع می شوند چرا که نزدیک خط مورب را دنبال می کند و به نظر نمی رسد که الگوی غیر خطی داشته باشد.
نتیجه :
با توجه به اهمیت نرمال بودن داده ها بررسی نرمال بودن داده ها بسیار مهم است. در این مطلب سعی کردیم با مثالی ملموس این موضوع را برای شما شرح دهیم. اگر شما هم علاقه مند به مباحث آماری هستید می توانید صفحه اینستاگرام آمار پیشرو را دنبال کنید. می توانید سوالات خود را در چت از ما بپرسید و همچنین در ادامه نظر خود را نسبت به این مطلب اعلام کنید.
")