
مدل سازی معادلات ساختاری با لیزرل(LISREL)
- نویسنده : لادن عباس نیا
- ارسال شده در: آوریل 25, 2020
- ارسال دیدگاه: ۸
[block id=”breadcrumb”]
مدل سازی معادلات ساختاری با لیزرل یکی از مباحث تخصصی علم آمار است. در این مطلب ابتدا مفهوم معادلات ساختاری و مفاهیم مرتبط آن ر بیان میکنیم و سپس مراحل مدل سازی معادلات ساختاری با لیزرل را با مثالی ملموس در نرم افزار نمایش و توضیح داده شده است.
مدل سازی معادلات ساختاری چیست؟
مدل سازی معادلات ساختاری (SEM) روشی آماری است که در بسیاری از رشتهها از جمله روانشناسی، علوم رفتاری، جامعهشناسی، علوم اجتماعی، اقتصاد، حسابداری، پزشکی و … مورد استفاده قرار میگیرد. این روش میتواند به عنوانی ترکیبی از تحلیل عاملی و رگرسیون یا تحلیل مسیر در نظر گرفته شود. نکته جالب در مورد مدلهای معادلات ساختاری، همان سازههای نظری (theoretical constructs) آن هستند که توسط متغیرهای پنهان نشان داده میشوند. نرمافزار لیزرل به عنوان اولین و معروفترین نرمافزار در این حوزه به طور گسترده مورد استفاده قرار میگیرد.
متغیر پنهان و متغیر آشکار:
متغیر پنهان یا مکنون (latent variable) متغیری است که به طور مستقیم قابل اندازهگیری نیست و باید به طور غیرمستقیم اندازهگیری شود. در مقابل متغیر پنهان، متغیر آشکار یا مشاهدهشده (observed variable) قرار دارد که به طور مستقیم قابل اندازهگیری است. به عنوان مثال برای متغیرهای آشکار، میتوان از متغیرهای فیزیکی مثل قد و وزن نام برد که ابزار مشخصی برای اندازهگیری آنها یعنی متر و ترازو وجود دارد. برای اندازهگیری قد و وزن افراد میتوان به طور مستقیم از متر یا ترازو استفاده کرد.
اما برای متغیرهای انتزاعی چهطور؟ فرض کنید میخواهیم فرهنگ شهروندی افراد را بررسی کنیم. فرهنگ شهروندی یک مفهوم فیزیکی نیست که برای آن ابزار خاصی وجود داشته باشد و توسط آن، فرهنگ شهروندی افراد را به طور مستقیم اندازهگیری کنیم. لذا فرهنگ شهروندی، یک متغیر پنهان است و برای اندازهگیری آن باید به طور غیرمستقیم از یک تعداد متغیر آشکار بهرهگیری کنیم. بدین صورت که تحقیق میکنیم و درمییابیم فرهنگ شهروندی افراد بر یک تعداد از ویژگیهای آنان تأثیرگذار است.
به طور مثال، فرهنگ شهروندی بالا در افراد منجر به رفتارهایی مثل دفع ضابطهمند زبالهها، رعایت الگوی مناسب مصرف انرژی و پرداخت بهنگام عوارض نوسازی توسط آنها میشود. این سه ویژگی را میتوان به عنوان متغیرهای آشکار در نظر گرفت. زیرا در مورد آنها میتوان به طور مستقیم از افراد سوال کرد و بدین طریق میزان آن متغیرها را مورد سنجش قرار داد.
زیرا در مورد آنها میتوان به طور مستقیم از افراد سوال کرد و بدین طریق میزان آن متغیرها را مورد سنجش قرار داد. مثلاً میتوان پرسشنامهای را طراحی کرد و این ویژگیها را به عنوان سوالات این پرسشنامه (item) قرار داد. این پرسشنامهها در اختیار افراد قرار میگیرند و افراد، میزان هر یک از این موارد را درباره خود با نمراتی مشخص میکنند. سپس با استفاده از نمرات جمعآوری شده، میتوان در نهایت فرهنگ شهروندی را اندازهگیری کرد. در ادبیات معادلات ساختاری، متغیرهای آشکار با شکل مربع یا مستطیل، و متغیرهای پنهان با شکل دایره یا بیضی نشان داده میشود (شکل بعد را ببینید).
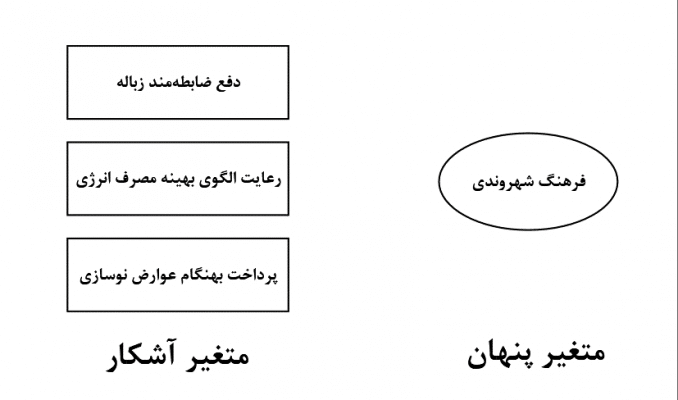
سازه :
هر متغیر پنهان به همراه متغیرهای آشکار خود، یک سازه (construct) را تشکیل میدهد. در شکل بعد، سازه فرهنگ شهروندی به نمایش درآمده است. در این سازه، متغیر پنهان فرهنگ شهروندی با شکل بیضی به نمایش درآمده است. متغیرهای آشکار شامل سوالات پرسشنامه آن و بدین صورت هستند: دفع ضابطهمند زبالهها به عنوان سوال ۱، رعایت الگوی مناسب مصرف انرژی به عنوان سوال ۲ و پرداخت بهنگام عوارض نوسازی به عنوان سوال ۳. این متغیرها با شکل مستطیل نشان داده شدهاند.
سازه فرهنگ شهروندی را در شکل بعد میتوانید مشاهده کنید. همان طور که در این شکل مشاهده میشود، از فرهنگ شهروندی به هر کدام از متغیرهای آشکار یک پیکان یکطرفه ترسیم شده است. این پیکان نشاندهنده تأثیرپذیری هر کدام از متغیرهای آشکار از فرهنگ شهروندی است که در قسمت قبل و در تعریف متغیر پنهان بیان شد.
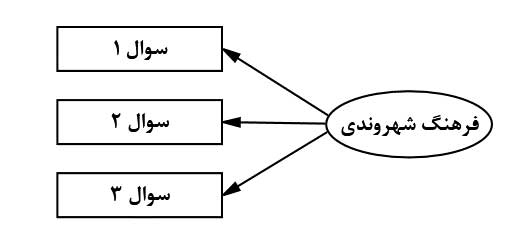
مدل تحلیل مسیر:
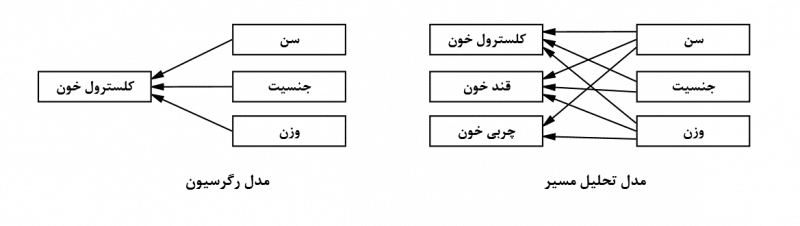
مدلهای معادلات ساختاری، به عنوان تعمیمی از مدلهای رگرسیونی شناخته میشوند. در رگرسیون، اثر یک یا چند متغیر مستقل بر یک متغیر وابسته سنجیده میشود. البته در مدلهای رگرسیون، همگی متغیرها از نوع آشکار هستند. به عنوان مثال، فرض کنید میخواهیم اثر سن، جنسیت و وزن افراد را بر میزان کلسترول خون آنها بررسی کنیم. در این صورت سن، جنسیت و وزن به عنوان متغیرهای مستقل و میزان کلسترول به عنوان متغیر وابسته در نظر گرفته میشود.در این حالت، چون فقط یک متغیر وابسته وجود دارد، میتوان از مدل رگرسیون استفاده کرد.
با کلیک بر روی رگرسیون چیست؟ شما می توانید مفهوم آن را دریافت کنید.
اما اگر بیش از یک متغیر وابسته وجود داشته باشد چهطور؟ مثلاً در همین مثال اگر بخواهیم علاوه بر تاثیر متغیرهای مذکور بر کلسترول، اثر آنها بر چربی و قند خون افراد را نیز بررسی کنیم دیگر از مدل رگرسیون نمیتوانیم استفاده کنیم. در این حالت میتوانیم از مدل تحلیل مسیر (path analysis) استفاده کنیم. در مدل تحلیل مسیر، اثر چند متغیر آشکار بر چند متغیر آشکار دیگر سنجیده میشود. به عبارت دیگر، در مدل تحلیل مسیر همزمان چند متغیر مستقل و چند متغیر وابسته که همگی از نوع آشکار هستند حضور دارند.
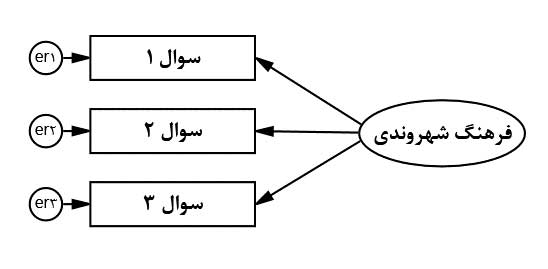
خطای اندازهگیری:
یکی از امتیازات مدلهای معادلات ساختاری، در نظر گرفتن خطای اندازهگیری (measurement error) در آنها است. وقتی میگوییم یک متغیر پنهان (مثلاً فرهنگ شهروندی) توسط تعدادی متغیر آشکار (سوالات پرسشنامه فرهنگ شهروندی) اندازهگیری میشود، در این صورت باید بپذیریم که این اندازهگیری میتواند به طور صد در درصد درست نباشد و شامل مقداری خطا باشد. این خطا، تحت عنوان خطای اندازهگیری شناخته میشود.
در هر سازه، به ازای هر متغیر آشکار یک خطای اندازهگیری در نظر گرفته میشود. به عنوان مثال، سازه فرهنگ شهروندی در شکل بعد به همراه خطاهای اندازهگیری یعنی er1، er2 و er3 نشان داده شده است. همان طور که میبینید، خطاهای اندازهگیری با شکل دایره نشان داده شدهاند که یعنی از نوع متغیرهای پنهان هستند. چون خطای اندازهگیری به طور مستقیم قابل اندازهگیری نیست، به صورت متغیر پنهان در نظر گرفته میشود.
مدل اندازهگیری:
مدل اندازهگیری شامل یک یا تعدادی از متغیرهای پنهان به همراه متغیرهای آشکار آنها است که روابط بین متغیرهای پنهان و متغیرهای آشکار را بررسی میکند. در این مدلها، روابط بین متغیرهای پنهان به صورت دوسویه (کوواریانس) در نظر گرفته میشود. مدل اندازهگیری به پژوهشگر امکان میدهد چگونگی تبیین سازههای مورد نظر توسط متغیرهای آشکار را ارزیابی کند. به عنوان مثال، فرض کنید میخواهیم روانشناسی شغلی را برای دانشجویان کارشناسی دانشگاهها بررسی کنیم.
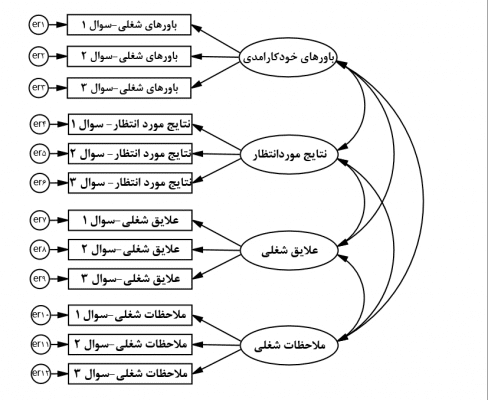
طبق نظر پژوهشگران فعال در این حوزه، روانشناسی شغلی از چهار سازه باورهای خودکارامدی، نتایج مورد انتظار، علایق شغلی و ملاحظات شغلی تشکیل میشود. هر کدام از این سازهها توسط یک متغیر پنهان به همراه متغیرهای آشکار آن در نظر گرفته میشود که متغیرهای آشکار همان سوالات پرسشنامه هستند که توسط پژوهشگران طراحی و در اختیار دانشجویان برای پاسخدهی قرار داده میشود.
مدل اندازهگیری روانشناسی شغلی در شکل بعد به نمایش درآمده است. پژوهشگران با استفاده از این مدل و روشهای ارزیابی آن میتوانند بررسی کنند آیا پرسشنامهای که طراحی کردهاند از اعتبار لازم برای سنجش روانشناسی شغلی و سازههای آن برخوردار است یا خیر. ارزیابی مدل اندازهگیری در قالب تحلیل عاملی تأییدی (confirmative factorial analysis) انجام میشود که شامل بررسی معیارها و استانداردهایی است که اعتبار مدل اندازهگیری را مورد سنجش قرار میدهند.
مدل ساختاری:
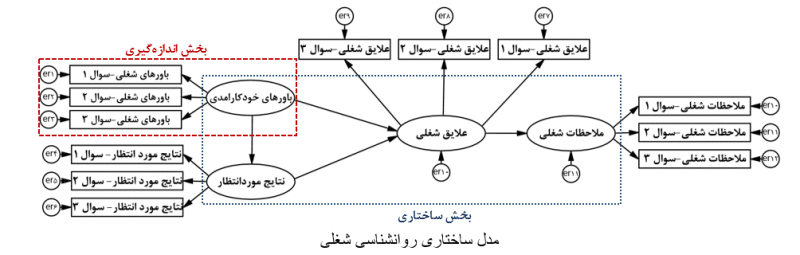
در مدل ساختاری به بررسی روابط متغیرهای پنهان با یکدیگر پرداخته میشود. این روابط بر اساس فرضیات پژوهشگر تعریف میشوند و بر پایه آنها مدل ساختاری پژوهش تشکیل میشود. روابط بین متغیرهای پنهان میتوانند از انواع دوسویه (کوواریانس)، مستقیم یا غیرمستقیم (میانجی) باشد. به عنوان مثال در بحث روانشناسی شغلی، فرضیات را بدین صورت در نظر میگیریم: ملاحظات شغلی تابعی از علایق شغلی هستند؛ علایق شغلی تحت تأثیر باورهای خودکارامدی و نتایج مورد انتظار است.
به عبارت دیگر، علایق شغلی تأثیر باورهای خودکارامدی و نتایج مورد انتظار را بر ملاحظات شغلی میانجیگیری میکند. مدل ساختاری مربوط به این فرضیات در شکل بعد به نمایش درآمده است. دقت کنید که یک مدل ساختاری، هم شامل بخش اندازهگیری و هم شامل بخش ساختاری میشود. این بخشها نیز در شکل بعد مشخص شده است.
مدل سازی معادلات ساختاری با لیزرل و مراحل آن
در طی ۴۰ سال گذشته، مدل، روشها و نرمافزار لیزرل با بحث مدل سازی معادلات ساختاری (SEM) مترادف شده است. این مدلها به پژوهشگران امکان میدهند نظریات خود را در زمینههای مختلفی همچون علوم اجتماعی، علوم مدیریت، علوم رفتاری، علوم زیستی، علوم آموزشی و … مورد ارزیابی قرار دهند. این نظریات معمولاً به صورت مدلهای نظری برای متغیرهای آشکار و پنهان فرمولبندی میشوند. اگر دادهها برای متغیرهای آشکار مدل نظری گرداوری شده باشد، آن گاه نرمافزار لیزرل میتواند برای برازش مدل به دادهها استفاده شود.
نرمافزار لیزرل یکی از اولین نرمافزارهای رایانهای بود که به طور گسترده برای مدل سازی معادلات ساختاری مورد استفاده قرار گرفت. این نرمافزار توسط آماردانان سوئدی، کارل یورِسکوگ و دَگ سوربون در دهه ۱۹۷۰ میلادی طراحی و پس از آنها بارها بروزآوری شد.
نرمافزار لیزرل بیشتر به صورت سینتکس-محور است، یعنی برای استفاده از دستورهای مختلف آن میتوان برنامه نوشت. فایل دستوری لیزرل شامل دستورهای مختلفی است که برای تعیین مواردی از قبیل ویژگیهای دادهها (تعداد متغیرهای ورودی، نوع متغیرها، نوع ماتریس، …)، ویژگیهای مدل (تعداد عناصر آزاد، ثابت یا محدود در ماتریس پارامترها مثلاً ماتریس کوواریانس)، ویژگیهای فایل خروجی (روش براورد مثل ماکسیمم درستنمایی یا کمترین مربعات وزنی) به کار میرود.

در نرمافزار لیزرل، بستهای به نام پرِلیز (PRELIS) قرار دارد که کارهایی را بدین شرح انجام میدهد: فایلهای دادههای خام برای تحلیل در لیزرل را آماده میکند، ماتریسهای همبستگی، کوواریانس، واریانس و کوواریانس مجانبی را براورد میکند، براوردهای بوتاسترپ عناصر ماتریسها را تولید میکند، مطالعات شبیهسازی برای تولید متغیرهایی راکه دارای ویژگیهای توزیعی مشخص باشند انجام میدهد.
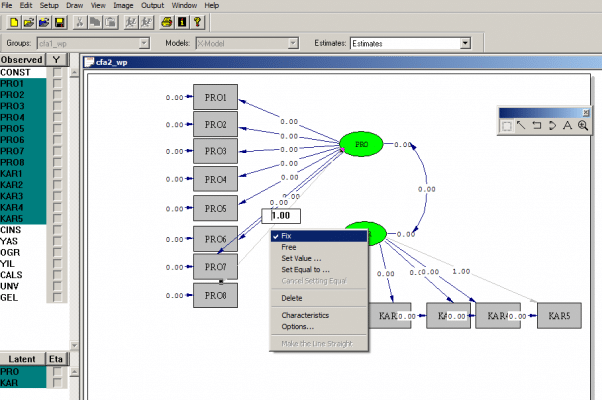
همان طور که گفته شد، نسخههای قدیمی لیزرل به صورت سینتکس-محور و برپایه جبر ماتریسی است، اما نسخههای جدیدتر (نرم افزار لیزرل ۸.۸ به بعد) دارای رابط کاربری گرافیکی شدهاند. این رابط شامل بخشهای مختلفی است که به کاربر اطلاعاتی راجع به مدل و دادهها میدهد و توسط آن میتوان مدل را با ابزارهای موجود، روی صفحه رسم کرد.
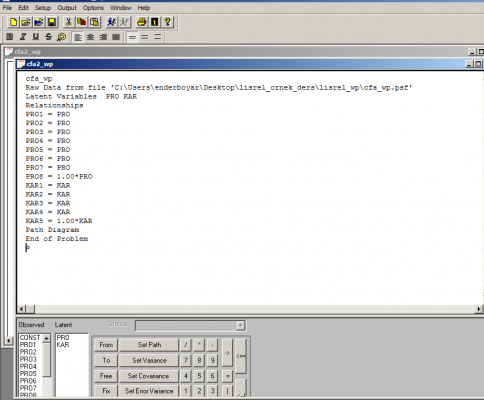
دیگر امکان جالبی که وجود دارد آن است که پس از رسم مدل، برنامه مربوط به آن توسط لیزرل به طور خودکار تولید میشود و در پنجرهای جداگانه در اختیار کاربر قرار میگیرد. پس از این مرحله میتوان مدل را اجرا کرد و براوردهای پارامترها و سایر خروجیها را به دست آورد. علاوه بر این، در لیزرل یک زبان برنامهنویسی دیگر به اسم سیمپلیس (SIMPLIS) نیز وجود دارد که مبتنی بر جبر ماتریسی نیست و سادهتر است. در نرمافزار لیزرل میتوان از حالت نمودار مدل (path diagram) به حالت سیمپلیس رفت و بالعکس.
آخرین نسخه عرضه شده تا کنون، لیزرل ۱۰ است که دیگرتنها به بحث معادلات ساختاری محدود نمیشود و از آن میتوان برای مباحث دیگر آماری همچون تحلیلهای پایهای آمار، مدلیابی سلسلهمراتبی خطی و غیرخطی، مدلیابی خطی تعمیمیافته و مدلیابی خطی برای دادههای چندسطحی استفاده کرد.
نکته مهم در استفاده از روش معادلات ساختاری، برقراری شرایط استفاده از این روش است. پیش از استفاده از معادلات ساختاری، ابتدا باید شرایط زیر برای دادهها بررسی شوند:
۱- مشاهدات باید مستقل باشند. به عبارت دیگر، دادههای مربوط به عضو حاضر در نمونه، با سایر اعضای حاضر در نمونه مستقل باشد.
۲- دادهها باید دارای توزیع چندمتغیره نرمال باشند.
۳- دادههای گمشده به صورت سیستماتیک در نمونه حضور نداشته باشند. یعنی عدم وجود اطلاعات برخی از اعضای نمونه به خاطر دلیل خاص و شناخته شده نباشد و تنها به صورت تصادفی اتفاق افتاده باشد.
۴- حجم نمونه کافی باشد.
۵- مدل مورد بررسی به درستی طراحی شده باشد.
امیدواریم این مطلب به شما کمک کند اما چنانچه ابهامی در مدل سازی معادلات ساختاری با لیزرل دارید می توانید از خدمات شرکتهای آماری استفاده کنید. کارشناسان شرکت آمارپیشرو آماده ارائه مشاوره و خدمات در زمینه روشهای معادلات ساختاری هستند. البته در مطالب آینده نیز، نحوه کار با نرمافزار لیزرل شامل ورود دادهها، طراحی مدل و تحلیل خروجی لیزرل آموزش داده خواهد شد.
در این مطلب سعی کردیم مدل سازی معادلات ساختاری با لیزرل را به شما آموزش دهیم اما برای دریافت مطالب بیشتر و بهتر می توانید صفحه اینستاگرام آمار پیشرو را دنبال کنید.
مدل سازی معادلات ساختاری چیست؟
مدل سازی معادلات ساختاری (SEM) روشی آماری است که به عنوانی ترکیبی از تحلیل عاملی و رگرسیون یا تحلیل مسیر در نظر گرفته میشود.
متغیر پنهان یا مکنون چیست؟
متغیر پنهان یا مکنون (latent variable) متغیری است که به طور مستقیم قابل اندازهگیری نیست و باید به طور غیرمستقیم اندازهگیری شود.
متغیر آشکار یا مشاهده شده چیست؟
متغیر آشکار یا مشاهدهشده (observed variable) به طور مستقیم قابل اندازهگیری است
مدل اندازهگیری چیست؟
مدل اندازهگیری شامل یک یا تعدادی از متغیرهای پنهان به همراه متغیرهای آشکار آنها است که روابط بین متغیرهای پنهان و متغیرهای آشکار را بررسی میکند.
مدل تحلیل مسیر چیست؟
در مدل تحلیل مسیر، اثر چند متغیر آشکار بر چند متغیر آشکار دیگر سنجیده میشود.
خطای اندازهگیری چیست؟
در هر سازه، به ازای هر متغیر آشکار یک خطای اندازهگیری در نظر گرفته میشود.
نرم افزار لیزرل چیست؟
نرمافزار لیزرل یکی از اولین نرمافزارهای رایانهای بود که به طور گسترده برای مدل سازی معادلات ساختاری مورد استفاده قرار گرفت.
چه زمانی از نرم افزار لیزرل استفاده میکنیم؟
اگر دادهها برای متغیرهای آشکار مدل نظری گرداوری شده باشد، آن گاه نرمافزار لیزرل میتواند برای برازش مدل به دادهها استفاده شود.

دیدگاه
مهيار,
20 مه 2021سلام
توضیحاتتون و شیوه ی بیانشون فوق العادست و خیلی مشکلاتم تو آمار برطرف شد.
خداقوت و تشکر فراوان.
مهدیه عرفانیان,
22 مه 2021سلام. از حسن نظر شما سپاسگزاریم و خوشحالیم که مطلب را آموزنده یافتهاید. با آرزوی موفقیت
زینب,
23 دسامبر 2021بسییییییییییییییییییییییییار عالی بود.بیش از پیش موفق باشید.
مهدیه عرفانیان,
27 دسامبر 2021با سلام. باعث افتخار است که این مطلب مورد توجه شما واقع شده است.
محمد,
31 دسامبر 2021سلام آیا این خطای اندازه گیری متغیر های آشکار در تحلیل عاملی حدود دارد یا مقدار دارد؟ممنون
پاپک,
04 اکتبر 2022درود
توضیحاتتون عااااااالی بود
روش بیان و منفک کردن مفاهیم هم عاااالی بود
سپاسگزارم
فقط
نگفتید اون عددی که روی بردارهای روابط بین متغیرها نوشته میشه، چیه !!
Lily,
03 فوریه 2023خیلی عالی توضیح دادین. خدا خیرتان دهد
رضا تیموری,
15 مه 2023ممنون از شما لیلی جان خوشحالیم بدردتون خورد