
چگونه داده کاوی با پایتون را به خوبی اجرا کنیم
- نویسنده : لادن عباس نیا
- ارسال شده در: آگوست 20, 2022
- ارسال دیدگاه: ۰
داده کاوی با پایتون یکی از روش های انجام داده کاوی است. در این مطلب ابتدا به مفهوم داده کاوی پرداختیم و سپس آن را با پایتون بررسی کردیم.
داده کاوی به زبان ساده همان کشف الگوی نهان دادههای بزرگ است. اخیرا علم داده کاوی به دلیل افزایش روز افزون دادهها و همچنین برای نظم دادن به پایگاههای بزرگ داده مورد توجه قرار گرفته است. سازمانهای خصوصی و دولتی برای بالابردن کارایی، مدیریت و برنامهریزی بهتر به داده کاوی روی آوردهاند.
کاربردهای مهم داده کاوی شامل تعیین توالی ژنومی، تجزیه و تحلیل شبکههای اجتماعی، تصویربرداری از جرم، کشف ترجیحات مصرف کننده، طبقهبندی مصرف کنندگان مختلف براساس فعالیت خریدشان و … میباشد.
برای آشنایی بیشتر با داده کاوی و کاربرد های آن بر روی این لینک کلیک کنید.
آشنایی با زبا برنامه نویسی پایتون
پایتون نرم افزار برنامه نویسی بسیار پرطرفدار و کارآمد در زمینه داده کاوی است. پایتون نسبت به سایر نرم افزارهای برنامه نویسی، نسبتا ساده به حساب میآید. یکی از مهم ترین مزایای زبان برنامه نویسی پایتون، کتابخانه دردسترس آن است که کتابخانههای مختص “یادگیری ماشین” بسیار زیادی برای آن تهیه شده است. زبان برنامه نویسی پایتون برای افرادی که تازه شروع به یادگیری کردهاند نیز مناسب است.
کتابخانه های داده کاوی با پایتون
برای یادگیری داده کاوی با پایتون ابتدا باید پایههای این زبان برنامه نویسی را بلد باشید. سپس به دنبال کتابخانههای اصلی برای داده کاوی با پایتون باشید. کتابخانههای زیادی برای داده کاوی با پایتون وجود دارد که مهمترین آن کتابخانه Numpy، کتابخانه Pandas، کتابخانه Scipy و کتابخانه Matplotlib است.
کتابخانه Numpy مختص آرایهها و ماتریسها است که عملیات مختلف را بر روی ماتریسها و آرایهها با سرعت زیادی انجام میدهد. کتابخانه Pandas مختص پیش پردازش دادهها و تحلیل سری زمانی است. کتابخانه Scipy برای بهینهسازی و یکپارچهسازی دادهها استفاده میشود و کتابخانه Matplotlib برای نمایش دادهها استفاده میشود که یکی از مهمترین مراحل داده کاوی همان رسم نمودار و نمایش دادههاست.
برای اینکه شما بخواهید داده کاوی را بیاموزید، ابتدا باید مراحل داده کاوی و مفهوم داده کاوی را به خوبی درک کنید که در فایل داده کاوی میتوانید مطالب را با جزئیات مطالعه کنید. برای انجام داده کاوی با هر نرم افزاری ابتدا باید دادهها آماده سازی شود که در این مرحله اقدامات زیر انجام میشود:
پاکسازی داده (Data Cleaning)
انتخاب زیر مجموعه ویژگی (Feature Subset Selection)
فیلترینگ نمونه ها (Sample Filtering)
نمونه گیری (Sampling)
تبدیل داده (Data Transformation)
گسسته سازی (Discretization)
کاهش ابعاد ((Dimensionality Reduction
انبوهش داده (Data Aggregation)
خلق ویژگی (Feature Creation)
قبلا کتابخانههای مهم در زبان برنامه نویسی پایتون را معرفی کردیم و مهمترین آن کتابخانه Pandas است که برای پیش پردازش دادهها استفاده میشود که شما میتوانید با استفاده از این کتابخانه مراحل ورود داده، بازیابی و اتصال داده، پاکسازی، فیلتر کردن، نرمال سازی و … را انجام دهید. پس از مرحله آماده سازی دادهها، نوبت به مصورسازی دادهها میرسد.
برای اینکه متوجه شویم چه اطلاعاتی در اختیار ما قرار دارد و اینکه چه الگویی باید روی آن پیاده کنیم، باید به صورت گرافیکی دادههای خود را به تصویر بکشیم. گرافهایی مرتبط با متغیرها رسم میکنیم تا بتوانیم برای الگوسازی، خوشهبندی، طبقهبندی و یا مدلسازی تصمیمگیری کنیم. در این مرحله میتوانیم از کتابخانه Matplotlib استفاده کنیم.
مهمترین تکنیکهای داده کاوی چیست؟
روشهای مختلفی برای ساخت مدلهای پیشبینی از مجموعه دادهها وجود دارد و دادهکاو باید مفاهیم پشت این تکنیکها و همچنین نحوه استفاده از کد برای تولید مدلها را درک کند. تعدادی از این تکنیکها شامل موارد زیر میشود:
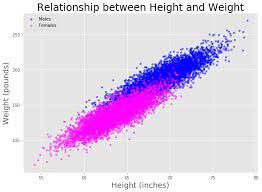
رگرسیون: در واقع رگرسیون تخمین روابط بین متغیرها با بهینهسازی کاهش خطا است. در پایین ارتباط بین قد و وزن را با استفاده از مدل رگرسیونی مشاهده می کنید.شما می توانید تعریف رگرسیون را در این لینک ببینید.
طبقهبندی: تشخیص اینکه یک شی متعلق به چه دستهای است با طبقهبندی انجام میشود. به عنوان مثال بررسی نمره اعتبار شخص و تایید رد یا درخواست وام.
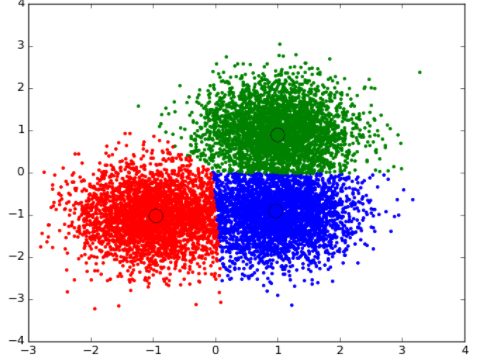
خوشهبندی: پیدا کردن گروهبندی اشیا براساس ویژگیهای شناخته شده آنها با استفاده از خوشهبندی انجام میشود. به عنوان مثال گروهبندی مشتریان براساس رفتار منحصر به فردشان که میتواند در تصمیمات استراتژی تجارت استفاده شود.
ارتباط و همبستگی: همبستگی به دنبال بررسی این است که آیا بین متغیرها روابط منحصربه فردی وجود دارد یا خیر؟ به عنوان مثال مردانی که در پایان هفته محصولات بهداشتی خریده بودند احتمال خرید نوشیدنی در آنها بسیار بیشتر بوده است. بنابراین فروشگاهها آنها را برای افزایش فروش نزدیک هم قرار میدادند.
تجزیه و تحلیل نقاط پرت: بررسی نقاط پرت برای بررسی علل و دلایل احتمالی پرتوهای گفته شده. به عنوان مثال استفاده از تجزیه و تحلیل در کشف تقلب و تلاش برای اینکه آیا الگویی از رفتار خارج از هنجار تقلب است یا خیر؟
داده کاوی با پایتون با دو الگوریتم
حال بیایید نحوه پیاده سازی داده کاوی با پایتون را با استفاده از دو الگوریتم رگرسیون وخوشهبندی با هم بررسی کنیم.
داده کاوی با پایتون با استفاده از مدل رگرسیون
مثالی از یک مدل رگرسیون در پایتون:
فرض کنید میخواهیم رابطه بین متراژ خانه و قیمت خانه را تخمین بزنیم. برای این کار باید ابزار مناسب داده کاوی را داشته باشیم. ابتدا Jupyter را نصب کنید. ما برای پاکسازی دادهها از ماژول Pandas Python استفاده میکنیم و ماژولهای کاربردی که قبلا توضیح دادیم را فراخوانی میکنیم.
In [1]:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
import seaborn as sns
from matplotlib import rcParams
%matplotlib inline
%pylab inline
سپس دادهها را فراخوانی و سپس دستورات مربوط به پاکسازی دادهها و سایر موارد را انجام میدهیم.
In [2]:
df =
pd.read_csv(‘/Users/michaelrundell/Desktop/kc_house_data.csv’)
df.head()
حال بررسی میکنیم که آیا دادههای ما مقادیر پوچی دارند یا خیر. در صورت وجود، مقادیر صفر را حذف یا فیلتر میکنیم.
In [3]:
df.isnull().any()
Out[3]:
id False
date False
price False
bedrooms False
bathrooms False
sqft_living False
sqft_lot False
…
dtype: bool
حال نوع داده را بررسی میکنیم و میخواهیم ببینیم آیا دادهها عددی هیتند یا شی؟
In [4]:
df.dtypes
Out[4]:
id int64
date object
price float64
bedrooms int64
bathrooms float64
sqft_living int64
sqft_lot int64
…
dtype: object
حال ببینیم دادهها منطقی هستند:
In [5]:
df.describe()
با استفاده از Matplotlib (plt) برای مشاهده توزیع قیمت مسکن و متر مربع هیستوگرام رسم میکنیم. پس از درک مجموعه دادهها ابتدا مدلهای stats را وارد میکنیم تا کمترین تابع برآوردگر رگرسیون مربعات را بدست آوریم. ماژول “حداقل مربعات معمولی” بیشترین کار را در مورد کوچک کردن اعداد برای رگرسیون در پایتون انجام می دهد.
Fig = plt.figure(figsize=(12, 6))
sqft = fig.add_subplot(121)
cost = fig.add_subplot(122)
sqft.hist(df.sqft_living, bins=80)
sqft.set_xlabel(‘Ft^2’)
sqft.set_title(“Histogram of House Square Footage”)
cost.hist(df.price, bins=80)
cost.set_xlabel(‘Price ($)’)
cost.set_title(“Histogram of Housing Prices”)
plt.show()
import statsmodels.api as sm
from statsmodels.formula.api import ols
وقتی برای تولید یک خلاصه رگرسیون خطی با OLS فقط با دو متغیر کدگذاری می کنید ، این فرمولی است که شما استفاده می کنید:
Reg = ols(‘Dependent variable ~ independent variable(s), dataframe).fit()
print(Reg.summary())
m = ols(‘price ~ sqft_living’,df).fit()
print (m.summary())
در نهایت با استفاده از خروجی میتوانیم ارتباط بین قیمت مسکن و متراژ آن را متوجه شویم. نتایج رگرسیون به صورت مصور در ادامه آمده است. خروجی رگرسیون برای بررسی صحت مدل رگرسیون و دادههایی که برای تخمین و پیشبینی استفاده میشود، مهم است اما تجسم رگرسیون یک گام برای برداشتن نتایج رگرسیون در قالب قابل هضمتر است. در اینجا تنها به خروجی نمودار پراکندگی خطوط رگرسیون بسنده میکنیم.
sns.jointplot(x=”sqft_living”, y=”price”, data=df, kind = ‘reg’,fit_reg= True, size = 7)
plt.show()
/Users/michaelrundell/anaconda/lib/python3.5/site-packages/statsmodels/nonparametric/kdetools.py:20: VisibleDeprecationWarning: using a non-integer number instead of an integer will result in an error in the future
y = X[:m/2+1] + np.r_[0,X[m/2+1:],0]*1j
مثالی از یک مدل خوشهبندی در پایتون
فرض کنید میخواهیم مجموعهای از اشیا (فوارههای آب) را گروهبندی کنیم. دادههای ما مربوط به فوران آب فوارههای یک پارک در مرکز شهر است که شامل دو ویژگی است یکی زمان انتظار بین فوران به دقیقه و دیگری طول فوران به دقیقه میباشد. برای این مدل از خوشهبندی با روش k-Means استفاده میکنیم. روش k-Means روشی ساده برای خوشهبندی است و تنها باید تعداد خوشهها (K) را از قبل مشخص کنیم.
مراحل انجام خوشهبندی به روش k-Means به صورت زیر است:
پس از مشخص شدن تعداد خوشهها، ابتدا K نقطه به صورت تصادفی به عنوان مرکز خوشه انتخاب میشوند و فاصله تمامی نقاط با مراکز انتخابی محاسبه میشود و نهایتا نقاطی با کمترین فاصله با مرکز خوشه در یک گروه قرار میگیرند. سپس برای هر خوشه، میانگین جدیدی محاسبه میشود و آن میانگین به عنوان مرکز خوشه درنظر گرفته میشود. این مراحل تا آنجا ادامه مییابد که فاصله میانگینهای دو مرحله پی در پی کمتر از سطح حساسیت شود.
برای انجام الگوریتمهای خوشهبندی در پایتون ابتدا باید ماژول Sci-kit Learn را نصب کنید.
ابتدا فایل csv را فراخوانی میکنیم و ۵ ورودی اول را در ادامه مشاهده میکنیم.
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import sklearn
from sklearn import cluster
%matplotlib inline
faithful = pd.read_csv(‘/Users/michaelrundell/Desktop/faithful.csv’)
faithful.head()
Out:
eruptions waiting
۰ ۳.۶۰۰ ۷۹
۱ ۱.۸۰۰ ۵۴
۲ ۳.۳۳۳ ۷۴
۳ ۲.۲۸۳ ۶۲
۴ ۴.۵۳۳ ۸۵
در این مثال قبلا پاکسازی داده انجام شده است و ما به سراغ متصورسازی دادهها و خوشهبندی آنها میرویم.
faithful.columns = [‘eruptions’, ‘waiting’]
plt.scatter(faithful.eruptions, faithful.waiting)
plt.title(‘Old Faithful Data Scatterplot’)
plt.xlabel(‘Length of eruption (minutes)’)
plt.ylabel(‘Time between eruptions (minutes)’)
Out[19]:
با توجه به نمودار بالا که یک طرح پراکنده است تعداد خوشههای انتخابی ۲تاست. بنابراین مقدار K را برابر ۲ قرار میدهیم و دستورات خوشهبندی را انجام میدهیم.
faith = np.array(faithful)
k = 2
kmeans = cluster.KMeans(n_clusters=k)
kmeans.fit(faith)
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
for i in range(k):
# select only data observations with cluster label == i
ds = faith[np.where(labels==i)]
# plot the data observations
plt.plot(ds[:,0],ds[:,1],’o’, markersize=7)
# plot the centroids
lines = plt.plot(centroids[i,0],centroids[i,1],’kx’)
# make the centroid x’s bigger
plt.setp(lines,ms=15.0)
plt.setp(lines,mew=4.0)
plt.show()
معنی دو خوشه بالا را به صورت خلاصه بیان میکنیم. خوشه سبز متشکل از فوارههای کوتاه و دارای زمان انتطار کوتاه بین فوارههاست که میتواند ضعیف یا سریع آتش باشد. درحالی که خوشه آبی را میتوان فورانهای قدرت نامید.
داده کاوی شامل تعدادی از تکنیکهای مدلسازی پیشبینی شده است و شما میتوانید از انواع نرمافزارهای داده کاوی استفاده کنید. ما در اینجا تعدادی از دستورات مربوط به الگوریتمهای خوشهبندی و رگرسیون را بیان کردیم.

دیدگاه بگذارید