
الگوریتمهای بدون نظارت
- نویسنده : لادن عباس نیا
- ارسال شده در: ژوئن 1, 2025
- ارسال دیدگاه: ۲
تعریف
یادگیری بدون نظارت: یادگیری بدون نظارت (Unsupervised Learning) یکی از روشهای یادگیری ماشین است که در آن مدل بدون داشتن برچسبهای از پیش تعیینشده، الگوها و ساختارهای پنهان را در دادهها کشف میکند. برخلاف یادگیری نظارتشده که مدل از دادههای دارای برچسب (ورودی-خروجی مشخص) برای یادگیری استفاده میکند، در یادگیری بدون نظارت، مدل فقط دادههای ورودی را دریافت کرده و سعی میکند شباهتها، گروهبندیها یا ویژگیهای مهم را شناسایی کند.
تفاوت با یادگیری نظارتشده: در یادگیری نظارتشده، برچسب داریم، ولی در یادگیری بدون نظارت، مدل باید خودش گروهها یا ویژگیهای مهم را پیدا کند.
فرض کنید صد نفر آدم پیش روی شماست و من به شما گفته ام که این آدم ها را به ۲ گروه تقسیم کنید.
احتمالا شما می گویید که خب بر چه اساس یا خصوصیتی این کار را انجام دهم ؟ و من میگویم خودتان می دانید.
اینکه من میگم خودتان میدانید یعنی هیچ برچسبی به شما ندادم، با وجود اینکه انتظار دارم شما این افراد رو گروه بندی کنید.
فرض کنید وارد یک مهمانی شده اید و هیچکس را نمیشناسید. بعد از مدتی، متوجه میشوید که چند گروه تشکیل شده است:
یک گروه درباره ورزش صحبت میکند.
یک گروه درباره موسیقی بحث میکند.
یک گروه در حال صحبت درباره فیلم هستند.
شما بدون اینکه کسی به شما بگوید، توانستید بفهمید که افراد بر اساس علایق خود گروهبندی شده اند.
این دقیقاً کاری است که یادگیری بدون نظارت انجام میدهد!
برخی از الگوریتمهای بدون نظارت شامل خوشه بندی، کاهش بعد و مدلسازی موضوعی هستند.
خوشه بندی
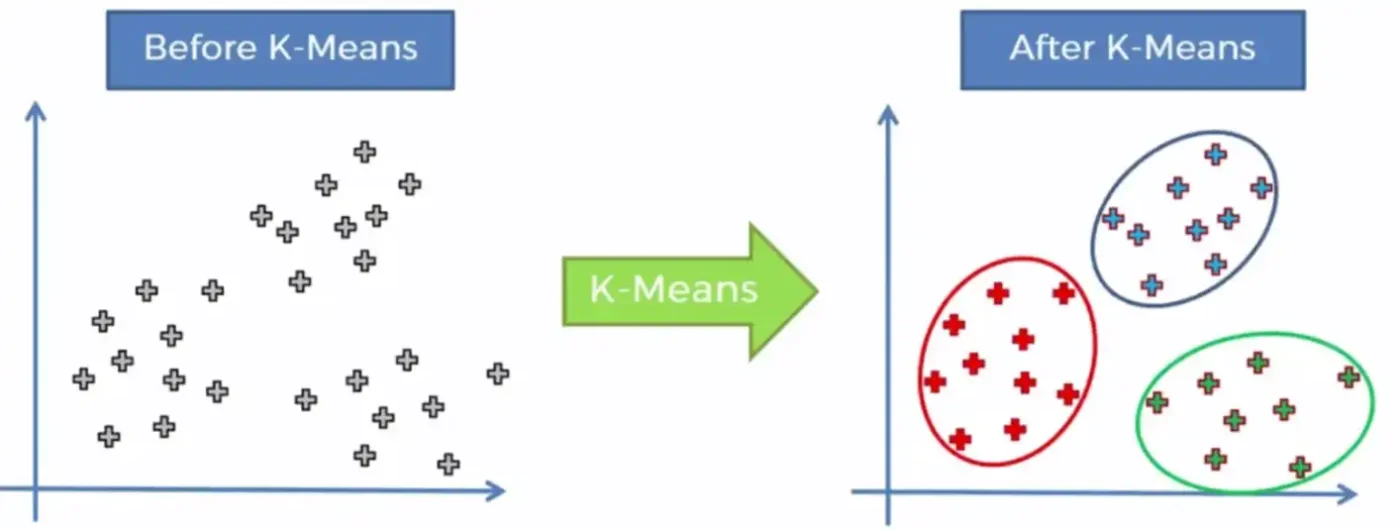
خوشه بندی یکی از مهمترین الگوریتمهای بدون نظارت است. در این الگوریتم، اشیاء مشابه در یک گروه یا «خوشه» قرار میگیرند. خوشه بندی در شناسایی الگوهای پنهان، دادههای ایمن و جمعآوری اطلاعات برای آموزش الگوریتمهای دیگر مؤثر است. مثالی از یک الگوریتم خوشه بندی، الگوریتم K-Means است.
فرض کنید مدیر باشگاه ورزشی هستید و میخواهید بدانید مشتریان چه نوع تمرینهایی را بیشتر دوست دارند. بعد از بررسی دادهها، میفهمید که مشتریان به سه گروه تقسیم میشوند:
کسانی که بیشتر بدنسازی کار میکنند.
کسانی که تمرکز روی ورزشهای هوازی دارند.
کسانی که فقط برای تفریح و تناسب اندام می آیند.

K-Means چطور کار میکند؟
تعدادی مرکز خوشه مشخص میکند و دادهها را به نزدیکترین مرکز نسبت میدهد.
مرحله به مرحله این مراکز را جابهجا میکند تا بهترین گروهبندی را پیدا کند.
کاهش بعد
کاهش بعد یک فرایند است که ابعاد ویژگیهای داده را کاهش میدهد و در نتیجه مقدار اطلاعات در دادهها کاهش مییابد. از این الگوریتم برای کاهش پیچیدگی محاسباتی و زمان موردنیاز برای پردازش دادههای غیرضروری استفاده میشود.
الگوریتم PCA یا تجزیه مقادیر ویژه یک نمونه از الگوریتم کاهش بعد است.
چرا کاهش بعد مهم است؟
گاهی حجم دادهها خیلی زیاد است و پردازش آنها زمان می برد.
ما فقط به اطلاعات مهم و اصلی نیاز داریم.
تصور کنید یک گالری عکاسی آنلاین دارید. حجم عکسها زیاد است و کاربران به سختی میتوانند آن ها را دانلود کنند. با استفاده از PCA، میتوانید فقط اطلاعات مهم تصاویر را نگه دارید و بقیه جزئیات غیرضروری را حذف کنید. این باعث میشود که تصاویر سریعتر دانلود بشوند، بدون اینکه کیفیت کلی آنها خیلی پایین بیاید.

PCA چطور کار میکند؟
بررسی میکند که کدام ویژگیها بیشترین تاثیر را دارند.
ویژگیهای کماهمیت را حذف میکند تا دادهها سبکتر بشوند.
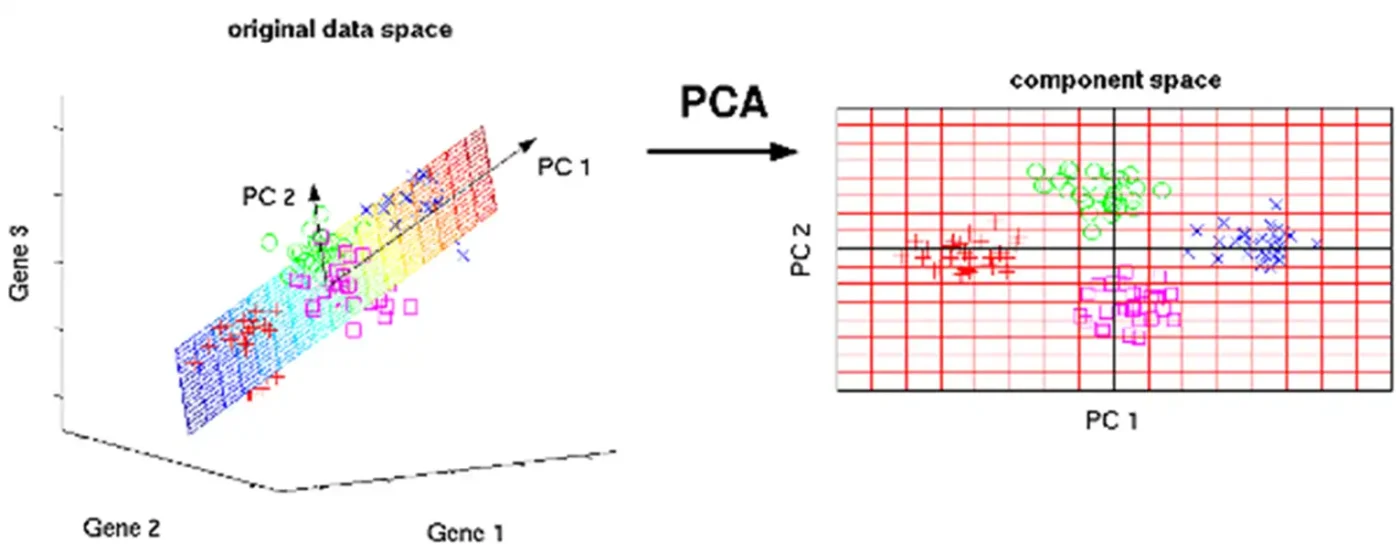
در اینجا هر نقطه یک نمونه داده است که ۳ ویژگی دارد ( قد، وزن و سن). اما فرض کنید در موضوعی که شما کار می کنید سن اصلا پارامتر مهمی نیست. پس PCA بدون اینکه اطلاعات خیلی مهم را حذف کند بعدهای اضافی را کم کرد.
کاربرد PCA در دنیای واقعی
فرض کنید یک شرکت خودروسازی میخواهد مشخص کند که چه عواملی روی میزان سوخت خودرو تأثیر دارند.
آن ها ۱۰ تا ویژگی دارند، مثل وزن خودرو، قدرت موتور، شکل بدنه، تعداد سرنشین و …
آن ها میخواهند فقط ۲ ویژگی اصلی را نگه دارند تا راحتتر مدلسازی کنند.
PCA بررسی میکند و نشان میدهد که مثلاً وزن خودرو و قدرت موتور، ۹۰٪ از تغییرات را توجیه میکنند، پس میتوانیم بقیه ویژگیها را حذف کنیم.

مدل سازی موضوعی
الگوریتم مدلسازی موضوعی (Latent Dirichlet Allocation) یا به اختصار (LDA) یک روش مدلسازی احتمالاتی برای به دست آوردن موضوعاتی است که ممکن است پشت یک مجموعۀ اسناد وجود داشته باشند. به طور خاص، در استفاده ازLDA برای هر سند در دادههای ورودی یک توزیع احتمالاتی برای «موضوعات» محتمل در آن سند بدست میآید. این الگوریتم برای دستهبندی محتوای یک مجموعه از اسناد در بسیاری از حوزهها نظیر بازاریابی، شبکههای اجتماعی و … مورد استفاده قرار میگیرد. مدلسازی موضوعی در این باره که هر یک از اسناد موجود در مجموعه، درباره چه موضوعی صحبت میکند تصمیمگیری میکند.
چرا مدل سازی موضوعی مهم است؟
در دنیای امروزی، حجم زیادی از دادههای متنی تولید میشود (نظرات کاربران، مقالات، پیامها و …).
ما نمیتوانیم همه این دادهها را دستی بررسی کنیم، پس الگوریتمهای یادگیری بدون نظارت کمک میکنند که موضوعات مهم استخراج بشوند.
LDA چطور کار میکند؟
هر متن را به ترکیبی از چند موضوع تقسیم میکند.
برای هر موضوع، کلمات پرتکرار را پیدا میکند و بر اساس آنها، موضوع را مشخص میکند.
به عنوان مثال، عملکرد الگوریتم LDA به این شکل است که برای هر سند، مجموعهای از لغات (واژگان یا کلمات) را در نظر میگیرد. به این مثال توجه کنید: فرض کنیم که یک سند متشکل از چند جمله است، مانند: «حیوانات خانگی مثل گربهها و سگها اغلب در خانههای ما زندگی می کنند». برای تحلیل این سند یا هر سند دیگر، LDA با فرض این که تمام واژگان در سند بهدست آمدهاند، تلاش میکند تا موضوعات محتمل در آن سند را مشخص کند. در این مثال، موضوع نهفته ممکن است «حیوانات خانگی» باشد.

فرض کنید مدیر یک فروشگاه اینترنتی هستید و هزاران نظر از مشتریان دارید. اما وقت ندارید همهشان را بخوانید. الگوریتم LDA به شما میگوید که، مثلاً:
۴۰٪ از نظرات درباره قیمت محصول است
۳۰٪ از نظرات درباره کیفیت کالا است
۲۰٪ از نظرات مربوط به ارسال و خدمات پس از فروش می باشد.


دیدگاه
محمد علی پور,
05 دسامبر 2025سلام و احترام بسیار عالی و مفید
مصطفی,
05 دسامبر 2025عالی