
یادگیری با نظارت
یادگیری با نظارت Supervised Learning)) یکی از روشهای یادگیری ماشین است که در آن، مدل یادگیری از دادههای آموزشی که دارای برچسب هستند استفاده میکند تا بتواند روی الگوها و قوانینی که در دادهها وجود دارد، تشخیص دهد و بتواند پیشبینی کند. در واقع، در این روش، برچسبها یا نتیجه مورد نظر برای هر نمونه داده به عنوان ورودی به مدل داده میشود تا مدل بتواند رابطهی میان ورودی و خروجی را یاد بگیرد. به طور کلی یادگیری با نظارت تلاش میکند تا رابطهها و وابستگیهای بین خروجی پیشبینی شده و ورودیها را به گونهای مدل کند که با یادگیری آنها بتوانیم مقدار خروجی برای یک داده جدید را پیشبینی کنیم.
برای مثال، فرض کنید که میخواهید یک مدل یادگیری را برای تشخیص تصاویر سگ و گربه ایجاد کنید. در این حالت، شما دادههای آموزشی که شامل تصاویر مختلف سگ و گربه هستند و دارای برچسب هستند را به مدل میدهید. مدل با تحلیل این دادههای آموزشی و روابطی که بین ویژگیهای تصاویر و برچسبها وجود دارد، میآموزد که در آینده بتواند تصاویر جدید را تشخیص دهد و بگوید که آیا تصویر حاوی سگ است یا گربه.

الگوریتمهای منتخب یادگیری با نظارت
رگرسیون خطی (Linear Regression)
مدلی که بین ورودیها و خروجی، یه رابطهی خطی برقرار میکنه. فرض میکنه خروجی (مثل قیمت، نمره، وزن) با افزایش یا کاهش ورودیها به صورت خطی تغییر میکنه.
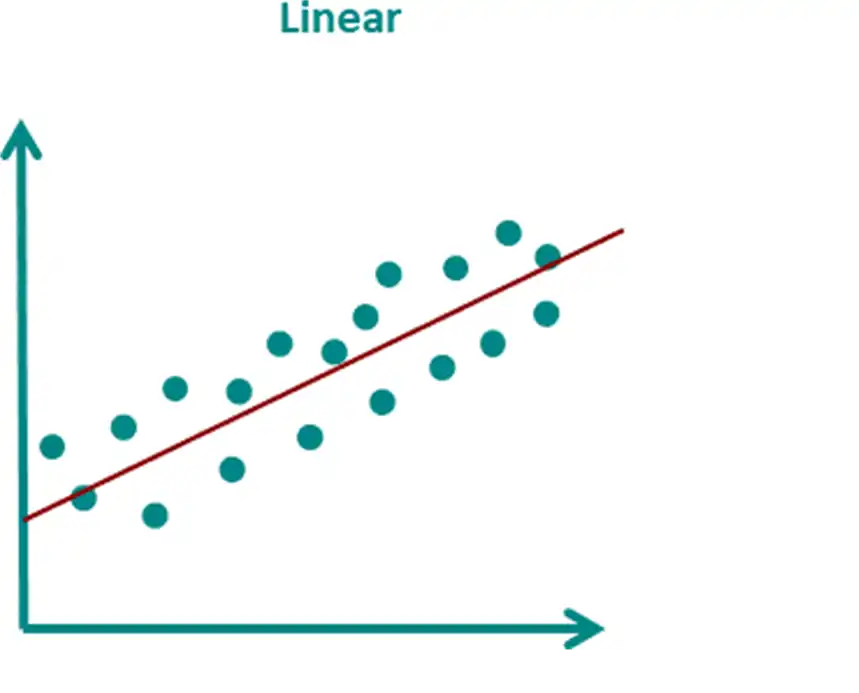
مثال واقعی:
میخوای بدونی که چطور ساعات مطالعه روی نمره امتحان تأثیر میذاره. دادههای دانشآموزها رو جمع میکنی (ساعات مطالعه و نمره). مدل یه خط میکشه که مثلاً بگه:
“هر ۱ ساعت مطالعه بیشتر، حدود ۲ نمره به نمره اضافه میکنه.”

نکته:
اگر رابطه خیلی ساده و مستقیم بین دادهها وجود داشته باشه، رگرسیون خطی خیلی خوب عمل میکنه. ولی برای روابط پیچیدهتر باید سراغ روشهای دیگه بریم.
رگرسیون غیرخطی (Nonlinear Regression)
وقتی رابطه بین ورودی و خروجی خطی نیست (مثلاً منحنی یا پیچیدهتره)، باید از مدلهای غیرخطی استفاده کنیم.
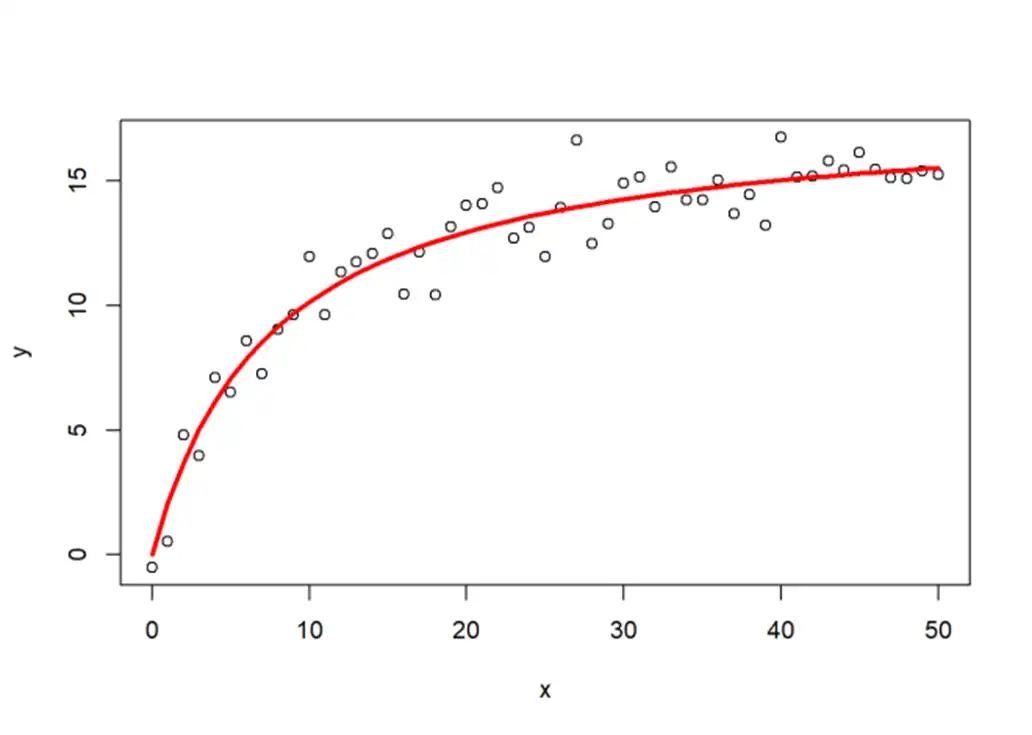
مثال کاربردی:
پیشبینی احتمال بستری شدن بیمار کرونایی با توجه به سن، وزن، و سابقه بیماری. این رابطه ساده نیست؛ ممکنه تا یه سنی خطری نباشه، ولی بعد از یه آستانه، احتمال بالا بره (یعنی منحنیوار تغییر کنه).

نکته:
مدلهای غیرخطی میتونن دقیقتر باشن، ولی تنظیم و آموزش اونها هم سختتره.
Kنزدیکترین همسایه (K-Nearest Neighbors / KNN)
وقتی یه داده جدید داری و میخوای پیشبینی کنی چه برچسبی داره، میری سراغ K تا از «نزدیکترین» دادههایی که قبلاً دیدی و از روی اونا تصمیم میگیری.

مثال واقعی:
میخوای بدونی یه خانه با متراژ ۱۰۰ متر، توی منطقه مشخص، چقدر قیمت داره. میری سراغ ۳ تا خونه که خیلی شبیه این خونه هستن (از نظر متراژ و منطقه)، قیمت اونارو نگاه میکنی، و میانگین میگیری.

رگرسیون لجستیک (Logistic Regression)
مدلی برای پیشبینی خروجیهای دستهای و دودویی مثل بله/خیر، سالم/بیمار، فعال/غیرفعال. برخلاف رگرسیون خطی که خروجی عدد میده، اینجا خروجی احتمال تعلق به یک دسته خاصه.
مثال واقعی:
بررسی اینکه آیا یه ایمیل اسپمه یا نه. مدل بر اساس ویژگیهای ایمیل (مثل تعداد لینکها، کلمات خاص، فرستنده) احتمال اسپم بودنش رو محاسبه میکنه.
ماشین بردار پشتیبان (SVM – Support Vector Machine)
یک الگوریتم یادگیری با نظارته که بیشتر برای دستهبندی (Classification) استفاده میشه. هدف اصلیش اینه که بهترین مرز یا خط جداکننده (Hyperplane) رو بین دو یا چند کلاس داده پیدا کنه؛ بهطوریکه فاصله بین نزدیکترین نقاط هر کلاس با این مرز بیشترین مقدار ممکن باشه.
به زبون سادهتر، دنبال یه خط (در ۲ بعد)، یا یک صفحه (در ۳ بعد)، یا یک ابرصفحه (در چندین بعد) میگرده که دادهها رو از هم جدا کنه و مطمئن باشه که این جداکننده، تا حد امکان از همهی کلاسها فاصلهی خوبی داره.
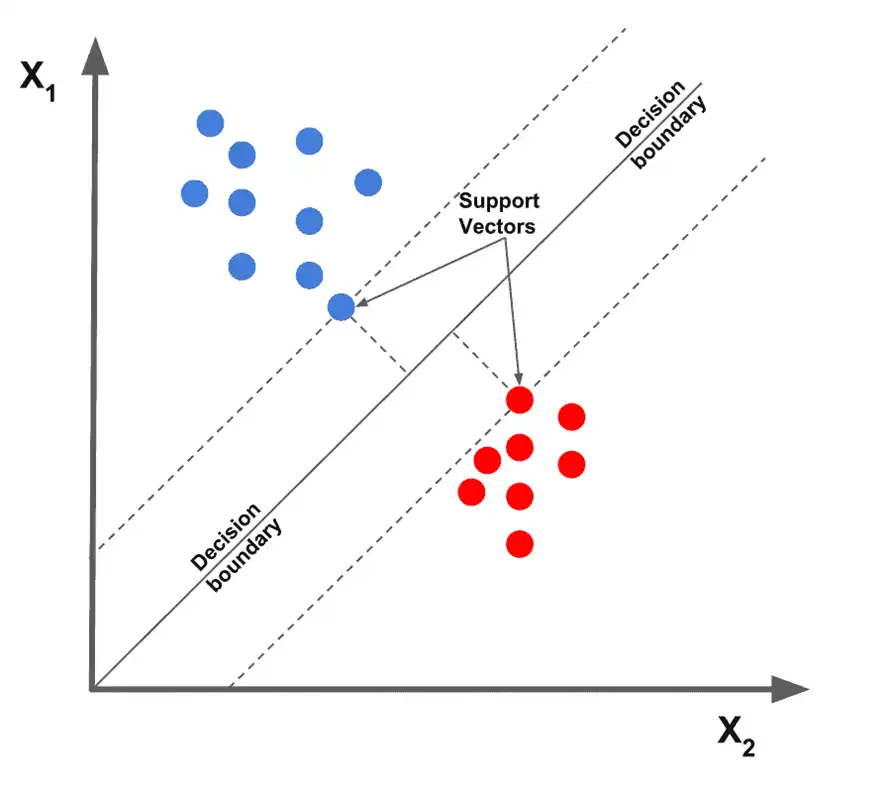
مثال واقعی برای درک بهتر:
فرض کن میخوای ایمیلها رو به دو دستهی اسپم و عادی تقسیم کنی. هر ایمیل چند ویژگی داره (تعداد لینک، طول متن، وجود کلمات خاص). SVM میاد و دنبال مرزی میگرده که این دو نوع ایمیل رو بهخوبی جدا کنه. مثلاً:
• ایمیلهایی با متن کوتاه و تعداد زیاد لینک → اسپم
• ایمیلهایی با متن طولانی و بدون لینک → غیر اسپم
SVM این تفاوتها رو یاد میگیره و سعی میکنه بینشون یه مرز مطمئن بکشه.
مثال تصویری ذهنی:
فرض کن یه برگه سفید داری که روش دایرهها و ستارهها کشیدی. اگه این دو نوع شکل کاملاً از هم جدا باشن، میتونی یه خط صاف بکشی بینشون.
حالا فرض کن بعضی دایرهها و ستارهها به هم نزدیکترن. SVM دنبال خطیه که با بیشترین فاصله از هر دو گروه رد بشه. یعنی حتی نزدیکترین دایره و ستاره هم ازش فاصله مناسبی داشته باشن.
اگر هم نشه با یه خط صاف جدا کرد، SVM با استفاده از تکنیکهای خاص دادهها رو به یه فضای جدید منتقل میکنه که در اون فضا بشه مرز صاف کشید ( به کمک کرنل ها )

برای امتیاز به این نوشته کلیک کنید!
[کل: 0 میانگین: 0]