
نمونه فصل چهارم پایان نامه(تحلیل آماری)
- نویسنده : لادن عباس نیا
- ارسال شده در: مارس 28, 2021
- ارسال دیدگاه: ۷
برای اینکه هر کاری را در اولین بار به شکل عالی انجام دهیم بهتر است نمونه های موفق آن را بررسی کنیم. نمونه فصل چهارم پایان نامه برای هر دانشجوی کارشناسی ارشد پژوهش محور از نان شب واجب تر است. نونه فصل چهارم پایان نامه کمک می کند تا این فصل از پایان نامه را به خوبی درک کنید و آن را بنویسید.
در فصل چهارم پایان نامه کدام اطلاعات نوشته می شود؟
در فصل چهارم پایان نامه، پژوهشگر دادههایی را که با استفاده از ابزارهای لازم و متناسب با هدف پژوهش جمعآوری کرده تجزیه و تحلیل میکند، که اینکار او در نهایت به تایید یا رد فرضیههای پژوهش منجر میشود. به طور کلی آنچه در فصل چهارم پایان نامه لازم است گزارش شود به دو بخش کلی آمار توصیفی و آمار استنباطی تقسیم میشود.
نحوه نگارش فصل چهارم پایان نامه.
در بخش آمار توصیفی برای تمامی متغیرهای پژوهش از جمله متغیرهای زمینهای، مستقل و وابسته و … آمارههای توصیفی مورد نیاز محاسبه و گزارش میشود. به عنوان مثال فراوانی و درصد فراوانی زنان و مردان شرکت کننده در پژوهش و یا میانگین و انحراف معیار متغیر وابسته کمی.
. همچنین برای تصمیمگیری برای انتخاب آزمون آماری مناسب، حذف دادههای پرت، روشن ساختن تکلیف دادههای گمشده، پراکندگی و چگونگی تغییرات دادههای هر متغیر نیز بررسی میشود. انتخاب آزمون آماری مناسب باید با توجه به ماهیت دادهها و نوع فرضیات پژوهش انجام شود و نتایج حاصل از محاسبات آماری برای پاسخگویی به فرضیات در بخش آمار استنباطی گزارش شود.

مساله مهم اینکه باید از تحلیل آماری انجام شده در فصل چهارم پایان نامه، یک برداشت نظری مرتبط با ادبیات پژوهش ایجاد شود و اشتراکات و تفاوت های آن با پیشینه پژوهش مقایسه شود. بنابراین یک تحلیل آماری هدفمند، کافی و کاملا مرتبط با اهداف و فرضیات پژوهش در فصل چهارم پایان نامه الزامی مینماید. در ادامه قصد داریم چند نمونه فصل چهارم پایان نامه انجام شده را نقد و بررسی کنیم.
در این نقد و بررسی ها علاوه بر موضوع نحوه جمع اوری داده ها و همچنین فرضیه های پژوهش، نوع تحلیل داده ها را بررسی کرده و به نقد اشتباهات آن می پردازیم.
نمونه فصل چهارم پایان نامه با آنالیز واریانس
اگر مفهوم آنالیز واریانس را نمی دانی اینجا کلیک کن و بعد ادامه بده
عنوان نمونه اول فصل چهارم پایان نامه “مقایسه اثربخشی درمان شناختی مبتنی بر ذهنآگاهی با درمان شناختی – رفتاری به شیوه گروهی بر کاهش خشم و پرخاشگری رانندگی” است. متناسب با عنوان و هدف اصلی پژوهش ۲ گروه آزمایشی تحت عنوان گروه درمانی شناختی مبتنی بر ذهنآگاهی و گروه درمانی شناختی – رفتاری داریم که مداخله دریافت میکنند و ۱ گروه کنترل داریم که هیچ مداخلهای دریافت نمیکند.
در ابتدای کار یعنی قبل از انجام جلسات مداخله درمانی، آزمودنیهای هر ۳ گروه پرسشنامههای مربوط به اندازهگیری خشم رانندگی و پرخاشگری رانندگی را تکمیل میکنند که نمرات حاصل، نمرات پیش آزمون این دو متغیر وابسته را میسازند.
سپس جلسات گروه درمانی شناختی مبتنی بر ذهنآگاهی و گروه درمانی شناختی – رفتاری به طور جداگانه بر روی یکی از گروههای آزمایشی اجرا میشود و پس از اتمام مداخله مجددا آزمودنیهای هر ۳ گروه پرسشنامههای مربوط به اندازهگیری خشم رانندگی و پرخاشگری رانندگی را تکمیل میکنند که نمرات حاصل، نمرات پس آزمون این دو متغیر وابسته را میسازند.
. در نهایت پرسشنامه ۱ ماه بعد در ۳ گروه اجرا میشود و نمرات حاصل نمرات پیگیری دو متغیر وابسته خشم رانندگی و پرخاشگری رانندگی را میسازند.
فرضیه های اصلی و فرعی پژوهش
فرضیههای اصلی:
فرضیه ۱: آزمودنیهای شرکتکننده در گروه درمانی شناختی مبتنی بر ذهنآگاهی در مقایسه با آزمودنیهای شرکتکننده در گروه درمانی شناختی – رفتاری در خشم رانندگی کاهش بیشتری نشان میدهند.
فرضیه ۲: آزمودنیهای شرکتکننده در گروه درمانی شناختی مبتنی بر ذهنآگاهی در مقایسه با آزمودنیهای شرکتکننده در گروه درمانی شناختی – رفتاری در پرخاشگری رانندگی کاهش بیشتری نشان میدهند.
فرضیات فرعی:
فرضیه ۱: آزمودنیهای شرکتکننده در گروه درمانی شناختی – رفتاری در مقایسه با آزمودنیهای شرکتکننده در گروه کنترل در خشم رانندگی کاهش بیشتری نشان میدهند.
فرضیه ۲: آزمودنیهای شرکتکننده در گروه درمانی شناختی – رفتاری در مقایسه با آزمودنیهای شرکتکننده در گروه کنترل در پرخاشگری رانندگی کاهش بیشتری نشان میدهند.
فرضیه ۳: آزمودنیهای شرکتکننده در گروه درمانی شناختی مبتنی بر ذهنآگاهی در مقایسه با آزمودنیهای شرکتکننده در گروه کنترل در خشم رانندگی کاهش بیشتری نشان میدهند.
فرضیه ۴: آزمودنیهای شرکتکننده در گروه درمانی شناختی مبتنی بر ذهنآگاهی در مقایسه با آزمودنیهای شرکتکننده در گروه کنترل در پرخاشگری رانندگی کاهش بیشتری نشان میدهند.
نحوه تحلیل داده ها
متناسب با فرضیات پژوهش، چگونگی فرایند جمعآوری داده و ماهیت دادههای پژوهش آزمون آنالیز واریانس اندازههای مکرر آمیخته و نرمافزار SPSS استفاده شده است. توجه کنید که اگر فقط پیش آزمون و پس آزمون داشتیم آزمون مناسب آنالیز کوواریانس و اگر فقط یک گروه آزمودنی داشتیم آزمون مناسب آنالیز اندازههای مکرر بود. بنابراین در پژوهش حاضر با استفاده از آزمون آنالیز اندازههای مکرر آمیخته روند تغییرات آزمودنیها طی ۳ مرحله پیش آزمون، پس آزمون و پیگیری و در ۳ گروه مقایسه شده است.
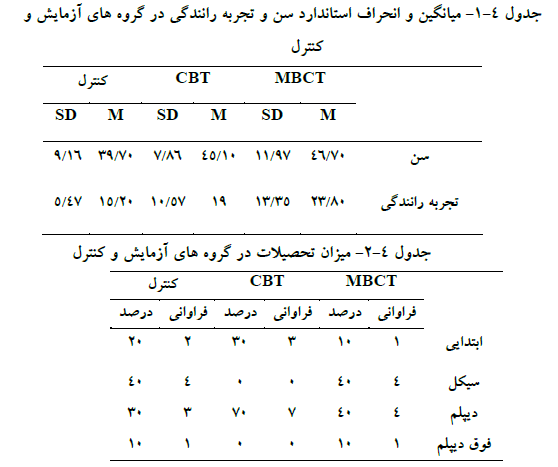
در بخش اول با استفاده از آزمون آنالیز واریانس میانگین متغیرهای زمینهای سن و تجربه رانندگی در ۳ گروه مقایسه شده است. همچنین با استفاده از آزمون کروسکال والیس میزان تحصیلات افراد در ۳ گروه مقایسه شده است که در نهایت مشخص شد بین ۳ گروه از نظر سن، تجربه رانندگی و میزان تحصیلات تفاوتی وجود ندارد و آزمودنیها در ۳ گروه کاملا همگن تقسیم شدهاند.
چنانچه بین آزمودنیها در هر یک از این متغیرها تفاوتی وجود داشت باید متغیر مورد نظر به عنوان متغیر کمکی یا کووریت وارد مدل آنالیز اندازههای مکرر میشد تا اثر آن کنترل شود. همچنین لازم است نمرات پیش آزمون دو متغیر خشم رانندگی و پرخاشگری رانندگی هم در ۳ گروه مقایسه شود تا ۳ گروه از لحاظ نمرات پیش آزمون هم همگن باشند.
بعد از بررسی پیشفرضهای لازم برای انجام آنالیز اندازههای مکرر آمیخته، برای پاسخگویی به فرضیه اصلی اول، زمان (نمرات پیش آزمون، پس آزمون و پیگیری خشم رانندگی) به عنوان عامل درون گروهی و گروه (شامل دو گروه درمان MBCT و CBT) به عنوان عامل بین آزمودنی وارد مدل شدند که نتایج به شرح زیر است:

بررسی فرضیات اصلی و فرعی نمونه فصل چهارم پایان نامه
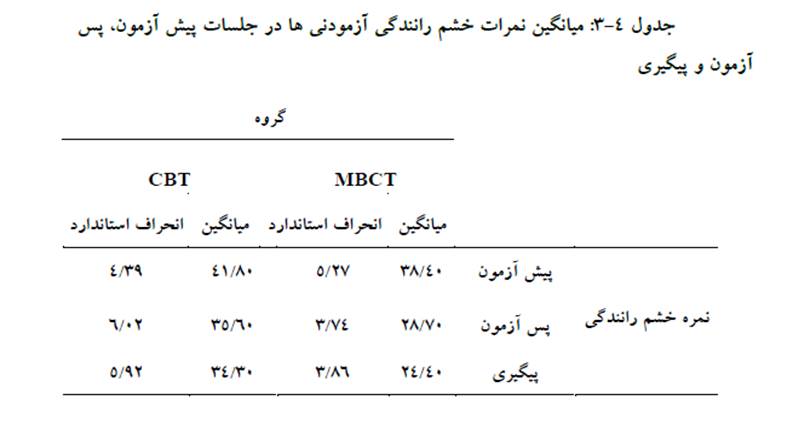
همانطور که از جدول ۴-۴ معلوم میشود، اثر زمان اندازهگیری به لحاظ آماری معنادار است چون مقدار معناداری متناظر با آن کوچکتر از ۰۵/۰ (۰۰/۰) بهدست آمده است. به عبارت دیگر میزان خشم رانندگی از جلسه پیش آزمون تا جلسه پیگیری کاهش معنادار داشته است. اثر تعامل زمان با گروه معنادار است چون مقدار معناداری متناظر با آن کوچکتر از ۰۵/۰ (۰۰/۰) بهدست آمده است. یعنی بین دو گروه در میزان کاهش خشم رانندگی از جلسه پیش آزمون تا جلسه پیگیری تفاوت معناداری وجود دارد.
همانطور که در جدول ۴-۳ مشاهده میشود، میانگین نمرات خشم رانندگی در گروه MBCT از ۴۰/۳۸ در پیش آزمون به ۷۰/۲۸ در پس آزمون و ۴۰/۲۴ در پیگیری کاهش یافته است و در مقابل میانگین نمرات خشم رانندگی در گروه CBT از ۸۰/۴۱ در پیش آزمون به ۶۰/۳۵ در پس آزمون و ۳۰/۳۴ در پیگیری کاهش یافته است.
. میزان کاهش خشم رانندگی در گروه MBCT بیشتر میباشد. به عبارت دیگر، در اثر گروه درمانی شناختی مبتنی بر ذهنآگاهی از جلسه پیش آزمون تا پس آزمون میزان خشم رانندگی آزمودنیهای گروه MBCT نسبت به گروه CBT کاهش بیشتری نشان داده است، این کاهش طی دوره پیگیری نیز حفظ شده است. بنابراین نمیتوان فرضیه اصلی اول را رد کرد.
برای پاسخگویی به فرضیه اصلی دوم، زمان (نمرات پیش آزمون، پس آزمون و پیگیری پرخاشگری رانندگی) به عنوان عامل درون گروهی و گروه (شامل دو گروه درمان MBCT و CBT) به عنوان عامل بین آزمودنی وارد مدل شدند.
برای پاسخگویی به فرضیات فرعی ۱ و ۲، زمان (نمرات پیش آزمون، پس آزمون و پیگیری خشم رانندگی و پرخاشگری رانندگی) به عنوان عامل درون گروهی و گروه (شامل دو گروه CBT و کنترل) به عنوان عامل بین آزمودنی وارد مدل شدند.
برای پاسخگویی به فرضیات فرعی ۳ و ۴، زمان (نمرات پیش آزمون، پس آزمون و پیگیری خشم رانندگی و پرخاشگری رانندگی) به عنوان عامل درون گروهی و گروه (شامل دو گروه MBCT و کنترل) به عنوان عامل بین آزمودنی وارد مدل شدند.
نقد وارد شده به فصل چهارم پایان نامه فوق میتواند این موضوع باشد که جدا کردن ۳ گروه MBCT، CBT و کنترل ضروری نبود. چرا که میتوان زمان را (نمرات پیش آزمون، پس آزمون و پیگیری پرخاشگری رانندگی و یا خشم رانندگی) به عنوان عامل درون گروهی و گروه را (شامل دو گروه درمان MBCT و CBT و گروه کنترل) به عنوان عامل بین آزمودنی وارد مدل کرد و با استفاده از آزمونهای تعقیبی مقایسات جفتی بین گروهها را انجام داد.
نمونه فصل چهار پایان نامه با استفاده از رگرسیون لجستیک
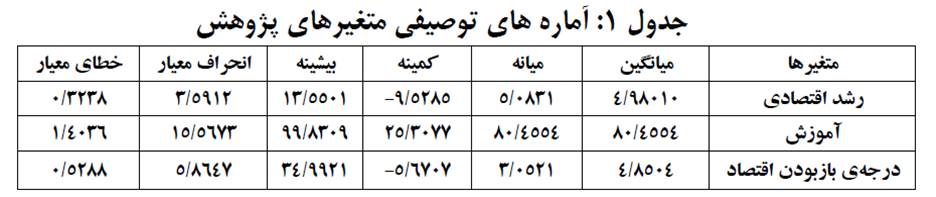
عنوان نمونه دوم فصل چهارم پایان نامه “عوامل مؤثر بر پذیرش استانداردهای بین المللی حسابداری در کشورهای درحال توسعه” است. نمونه آماری پژوهش شامل ۱۲۳ کشور از تمام کشورهای در حال توسعهای است که طبق دستهبندی بانک جهانی جز کشورهای با درآمد سرانه پایین یا متوسط هستند. متغیرهای مستقل تحقیق شامل رشد اقتصادی، آموزش، درجه باز بودن اقتصاد و وجود بازار سرمایه و متغیر وابسته پذیرش استانداردهای بینالمللی حسابداری است.
قبل از ادامه ماجرا شما می توانید مطلب رگرسیون چیست را در این لینک ببینید.
از میان متغیرهای فوق، رشد اقتصادی، آموزش و درجه باز بودن اقتصاد متغیر کمی، وجود بازار سرمایه و پذیرش استانداردهای بینالمللی حسابداری متغیر کیفی اسمی هستند. برای متغیر وجود بازار سرمایه دو سطح وجود یا عدم وجود بازار سرمایه و برای متغیر پذیرش استانداردهای بینالمللی حسابداری دو سطح پذیرش و عدم پذیرش در نظر گرفته شده است.
فرضیه اول: بین رشد اقتصادی و پذیرش استانداردهای بینالمللی حسابداری در کشورهای در حال توسعه، رابطه معناداری وجود دارد.
فرضیه دوم: بین آموزش و پذیرش استانداردهای بینالمللی حسابداری در کشورهای در حال توسعه، رابطه معناداری وجود دارد.
فرضیه سوم: بین درجه باز بودن اقتصاد و پذیرش استانداردهای بینالمللی حسابداری در کشورهای در حال توسعه، رابطه معناداری وجود دارد.
فرضیه چهارم: بین وجود بازار سرمایه و پذیرش استانداردهای بینالمللی حسابداری در کشورهای در حال توسعه، رابطه معناداری وجود دارد.
با توجه به ماهیت متغیرهای پژوهش و این موضوع که متغیر وابسته تحقیق کیفی اسمی و دارای دو سطح پذیرش و یا عدم پذیرش استانداردهای بینالمللی حسابداری است، و با توجه به نحوه نگارش فرضیات که به صورت بررسی رابطه بین متغیرهای مستقل و وابسته تحقیق نوشته شده است، آزمون آماری مناسب جهت پاسخگویی به فرضیات رگرسیون لجستیک است.
در این مطلب رگرسیون لجستیک را کامل توضیح داده ایم کافیست کلیک کنید.
در کنار رگرسیون لجستیک پژوهشگر از آزمون t گروههای مستقل جهت مقایسه میانگین متغیرهای رشد اقتصادی، آموزش و درجه باز بودن اقتصاد در میان دو دسته از کشورهایی که پذیرش استانداردهای بینالمللی حسابداری را داشتند و کشورهایی که پذیرش استانداردهای بینالمللی حسابداری را نداشتند استفاده کرده است که ضروری نبود. در واقع نقد وارد شده به فصل چهارم این پایان نامه همین موضوع است. چنانچه ما فرضیات را به صورت وجود یا عدم وجود رابطه معنادار بین متغیرهای مستقل و وابسته مینویسیم بایست از رگرسیون استفاده شود.
انواع آزمون t را می توانید در این مطلب ببینید.
به عنوان مثال در صورتی که نگارش فرضیه اول به صورت زیر صورت میگرفت:
“رشد اقتصادی در میان دو دسته از کشورهایی که پذیرش استانداردهای بینالمللی حسابداری را داشتند و کشورهایی که پذیرش استانداردهای بینالمللی حسابداری را نداشتند اختلاف معناداری دارد”
با استفاده از آزمون t این فرضیه را بررسی میکردیم. بهتر بود آزمون t گروههای مستقل فقط به عنوان تحلیل تکمیلی به این کار اضافه میشد و فرضیات با استفاده از رگرسیون پاسخ داده میشدند.
همچنین رابطه بین متغیرهای وجود بازار سرمایه و پذیرش استانداردهای بینالمللی حسابداری که دو متغیر کیفی اسمی هستند با استفاده از آزمون کای دو و ضریب همبستگی فی بررسی شده است. به نظر میرسد در ابتدا پژوهشگر قصد بررسی همبستگی میان متغیر مستقل کیفی و متغیر وابسته با استفاده از آزمون کای دو و بررسی همبستگی میان متغیرهای مستقل کمی و متغیر وابسته با استفاده از آزمون t گروههای مستقل را داشته است.
استفاده از آزمون t برای بررسی همبستگی میان یک متغیر کمی و یک متغیر اسمی دو سطحی (مثل جنسیت) و آزمون آنالیز واریانس برای بررسی همبستگی میان یک متغیر کمی و یک متغیر اسمی چند سطحی (مثل شغل) کار اشتباهی نیست اما باید توجه داشت ماهیت آزمون همبستگی با آزمونهای t گروههای مستقل و آنالیز واریانس و نحوه نگارش نتایج مربوط به هر یک متفاوت است.
در قسمت اول آمارههای توصیفی متغیرهای کمی رشد اقتصادی، آموزش و درجه باز بودن اقتصاد به شکل زیر گزارش شده است:
بررسی فرضیات نمونه فصل چهارم پایان نامه
در بخش آمار استنباطی پژوهشگر به سراغ پاسخگویی به فرضیات با استفاده از آزمون t گروههای مستقل به شکل زیر رفته است:
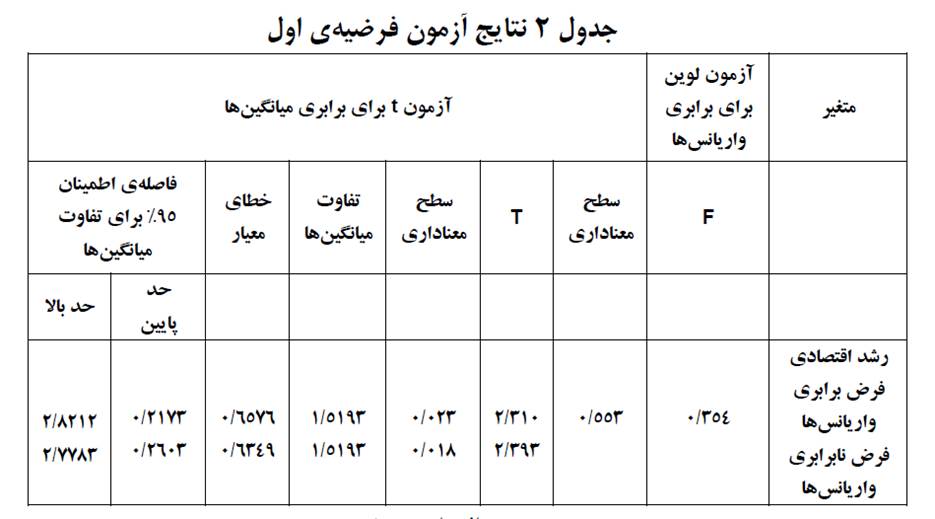
با توجه به نتایج بهدست آمده برای متغیر رشد اقتصادی، چون مقدار معناداری آزمون لوین بزرگتر از ۰۵/۰ (۵۵۳/۰) بهدست آمده است، نمیتوانیم فرض برابری واریانسهای دو گروه را رد کنیم و برای مقایسه میانگین رشد اقتصادی دو گروه از سطر اول که مربوط به برقراری فرض برابری واریانسها است استفاده میکنیم. در مقایسه میانگین رشد اقتصادی دو گروه آماره t برابر ۳۱۰/۲ و مقدار معناداری متناظر با آن کوچکتر از ۰۵/۰ (۰۲۳/۰) بهدست آمده است.
بنابراین میانگین متغیر رشد اقتصادی در کشورهایی که پذیرش استانداردهای بینالمللی حسابداری را داشتند و کشورهایی که پذیرش استانداردهای بینالمللی حسابداری را نداشتند اختلاف معناداری دارد. همانطور که ملاحظه میشود با نتیجه بهدست آمده نمیتوان چگونگی رابطه بین دو متغیر و نحوه تاثیرگذاری متغیر رشد اقتصادی بر پذیرش استانداردهای بینالمللی حسابداری را تعیین کرد. اما پژوهشگر برقراری فرضیه اول را با همین نتیجه تایید کرده است.
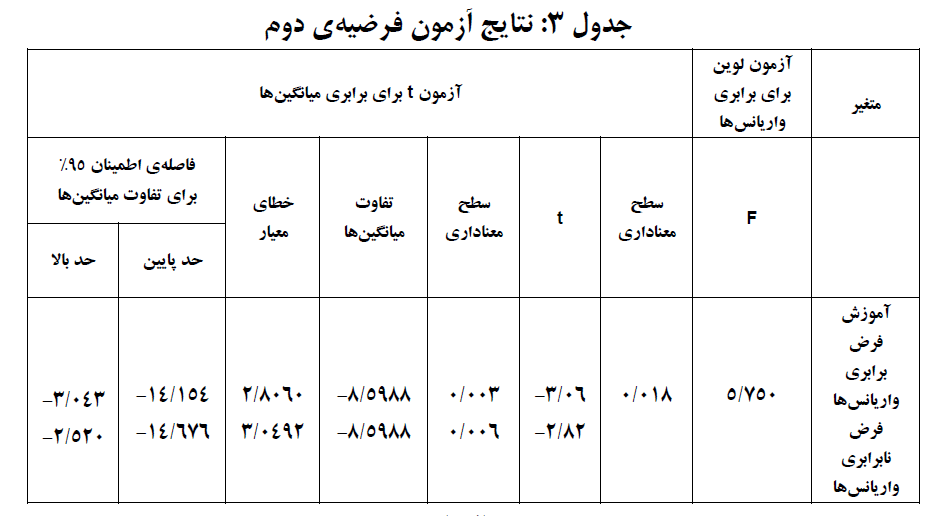
با توجه به نتایج بهدست آمده برای متغیر آموزش، چون مقدار معناداری آزمون لوین کوچکتر از ۰۵/۰ (۰۱۸/۰) بهدست آمده است، فرض برابری واریانسهای دو گروه را رد میکنیم و برای مقایسه میانگین رشد اقتصادی دو گروه از سطر دوم که مربوط به عدم برقراری فرض برابری واریانسها است استفاده میکنیم. در مقایسه میانگین آموزش دو گروه آماره t برابر ۸۲/۲- و مقدار معناداری متناظر با آن کوچکتر از ۰۵/۰ (۰۰۶/۰) بهدست آمده است. بنابراین میانگین متغیر آموزش در کشورهایی که پذیرش استانداردهای بینالمللی حسابداری را داشتند و کشورهایی که پذیرش استانداردهای بینالمللی حسابداری را نداشتند اختلاف معناداری دارد.
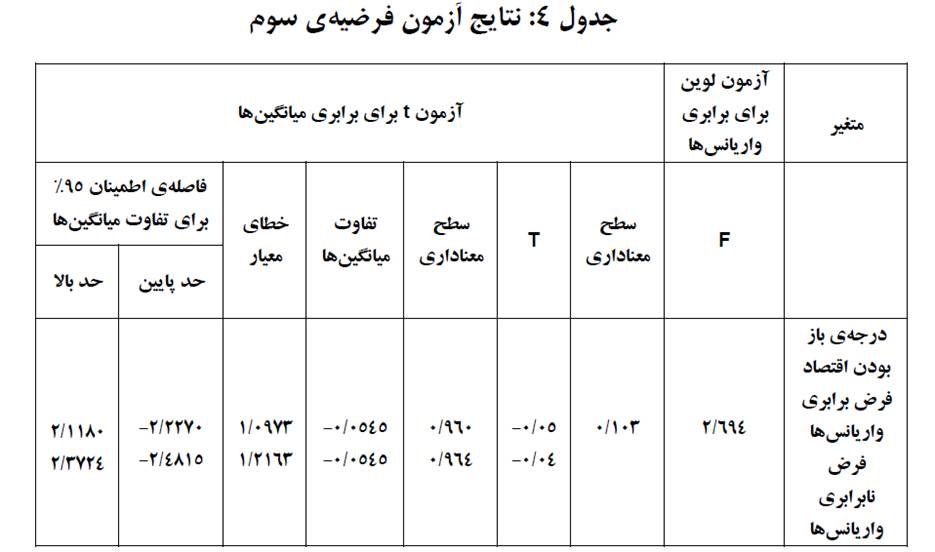
با توجه به نتایج بهدست آمده برای متغیر درجه باز بودن اقتصاد، چون مقدار معناداری آزمون لوین بزرگتر از ۰۵/۰ (۱۰۳/۰) بهدست آمده است، نمیتوانیم فرض برابری واریانسهای دو گروه را رد کنیم و برای مقایسه میانگین درجه باز بودن اقتصاد دو گروه از سطر اول که مربوط به برقراری فرض برابری واریانسها است استفاده میکنیم. در مقایسه میانگین درجه باز بودن اقتصاد دو گروه آماره t برابر ۰۵/۰- و مقدار معناداری متناظر با آن بزرگتر از ۰۵/۰ (۹۶۰/۰) بهدست آمده است. بنابراین میانگین متغیر درجه باز بودن اقتصاد در کشورهایی که پذیرش استانداردهای بینالمللی حسابداری را داشتند و کشورهایی که پذیرش استانداردهای بینالمللی حسابداری را نداشتند اختلاف معناداری ندارد.
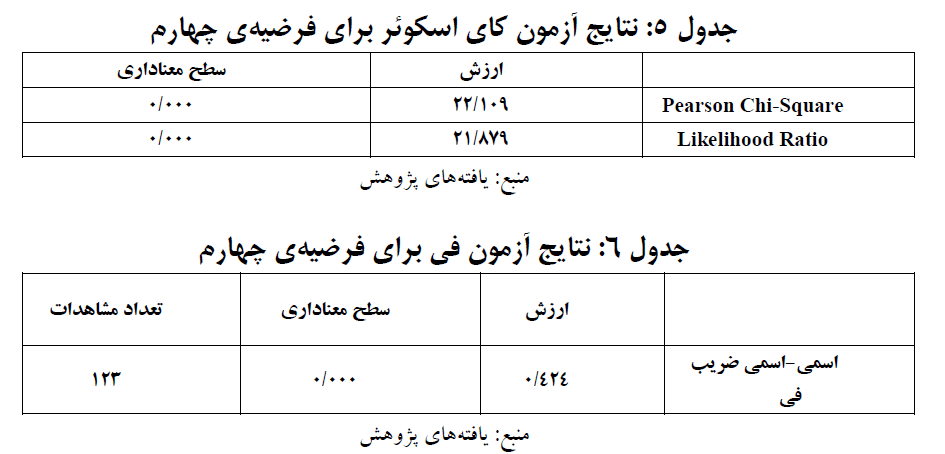
با توجه به نتایج بهدست آمده برای متغیر وجود بازار سرمایه، چون مقدار معناداری آزمون کای دو کوچکتر از ۰۵/۰ (۰۰۰/۰) بهدست آمده است، بنابراین میان دو متغیر وجود بازار سرمایه و پذیرش استانداردهای بینالمللی حسابداری رابطه معناداری برقرار است و ضریب همبستگی میان این دو متغیر ۴۲۴/۰ به دستآمده است.
در ادامه آزمون فرضیات با استفاده از رگرسیون لوژستیک به شرح زیر آمده است:

با توجه به نتایج بهدست آمده درصد پیشبینی درست مدل (دقت مدل) برابر ۲/۷۳ درصد به دست آمده است به این معنی که ۷۳ درصد از کشورها به درستی طبقهبندی شدهاند. ضریب تعیین نکلگرک برابر ۲۸۹/۰ است که یعنی ۲۹ درصد از تغییرات متغیر وابسته پذیرش استانداردهای بینالمللی حسابداری توسط متغیرهای مستقل رشد اقتصادی، آموزش، درجه باز بودن اقتصاد و وجود بازار سرمایه بیان میشود. با توجه به این که مقدار معناداری کوچکتر از ۰۵/۰ (۰۰۰/۰) بهدست آمده نتیجه میگیریم مدل برازش شده به لحاظ آماری معنادار است.
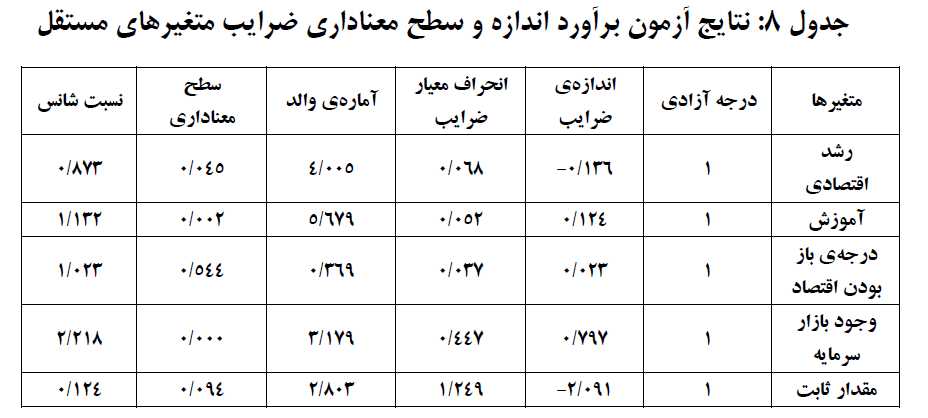
با توجه به نتایج بهدست آمده فقط برای متغیرهای رشد اقتصادی، آموزش و وجود بازار سرمایه مقدار معناداری کوچکتر از ۰/۰۵ بهدست آمده است. ضریب متغیر رشد اقتصادی ۰/۱۳۶- است به این معنی که با افزایش یک واحد در این متغیر، لگاریتم احتمال پذیرش به احتمال عدم پذیرش استانداردهای بینالمللی حسابداری ۰/۱۳۶ واحد کاهش مییابد. در واقع نسبت شانس پذیرش ۰/۸۷۳ برابر میشود.
. ضریب متغیر آموزش ۰/۱۲۴ است به این معنی که با افزایش یک واحد در این متغیر، لگاریتم احتمال پذیرش به احتمال عدم پذیرش استانداردهای بینالمللی حسابداری ۰/۱۲۴ واحد افزایش مییابد. در واقع نسبت شانس پذیرش ۱/۱۳۲ برابر میشود. ضریب متغیر وجود بازار سرمایه ۰/۷۹۷ است به این معنی که لگاریتم احتمال پذیرش به احتمال عدم پذیرش استانداردهای بینالمللی حسابداری در کشورهایی که بازار سرمایه دارند ۰/۷۹۷ واحد بیشتر از سایر کشورهاست.
به بیان دیگر احتمال پذیرش به احتمال عدم پذیرش استانداردهای بینالمللی حسابداری در کشورهایی که بازار سرمایه دارند ۲/۲۱۸ برابر کشورهایی است که بازار سرمایه ندارند. در نهایت اینگونه استنباط میکنیم فقط فرضیه سوم مربوط به متغیر درجه باز بودن اقتصاد رد میشود و شواهد کافی برای رد فرضیات اول، دوم و چهارم وجود ندارد.
نمونه فصل چهارم پایان نامه با تحلیل عاملی
عنوان نمونه سوم فصل چهارم پایان نامه “آسیبشناسی عدم گرایش پزشکان به بیمه عمر” است. متغیرهای مستقل پژوهش شامل آسیبهای فنی، شخصیتی، فرهنگی، بازاریابی و فروش و مالی بیمه عمر هستند که به وسیله پرسشنامه محقق ساخته اندازهگیری شدند. این متغیرهای مستقل عواملی هستند که ممکن است بر گرایش یا عدم گرایش پزشکان به بیمه عمر تاثیر بگذارند. سوالات پژوهش که باید به آنها پاسخ داده شود به شرح زیر است:
- علل عدم گرایش به بیمه عمر در ایران شامل چه مواردی است؟ پزشکان به چه دلایلی به بیمه عمر گرایش ندارند؟
- در بین عوامل موثر بر عدم گرایش پزشکان به بیمه عمر اولویتها بر چه اساسی است؟
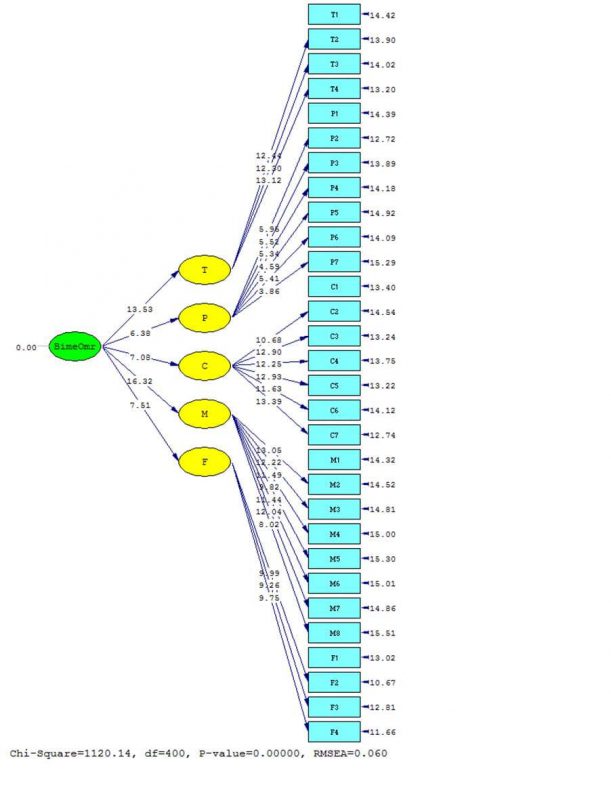
نکته قابل توجه در این فصل چهارم پایان نامه استفاده از متغیرهای مکنون است. متغیرهای مکنون یا پنهان متغیرهایی هستند که به طور مستقیم نمیتوان آنها را سنجید بلکه خود توسط متغیرهای مشاهده پذیر (گویه یا سوالات پرسشنامه) سنجیده میشوند. در پژوهش حاضر با توجه به اینکه متغیر وابسته عدم گرایش به بیمه عمر سوال پرسشنامه ندارد و قصد داریم عوامل موثر بر آن را شناسایی کنیم لازم است از تکنیک تحلیل عاملی تاییدی استفاده کنیم.
در قسمت آمار استنباطی در ابتدا تحلیل عاملی مرتبه اول برای بررسی روایی و پایایی پرسشنامه بررسی شده است. با توجه به نتایج به دست آمده بارهای عاملی به دست آمده در مدل معنادارند و شاخصهای نیکویی برازش مدل شامل شاخص RMSEA خوب است:
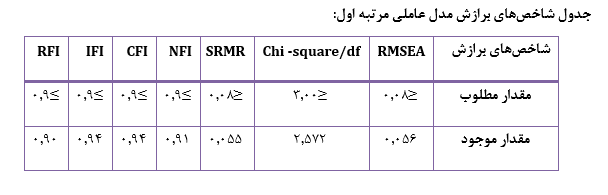
نقد وارد شده به این قسمت از کار این موضوع است که، دو شاخص GFI و AGFI دو شاخص مهم هستند که باید گزارش میشدند. ثانیا لازم است شاخصهای پایایی ترکیبی و AVE هم با استفاده از ضرایب بارهای عاملی محاسبه میشدند. مقدار قابل قبول برای پایایی ترکیبی ۷/۰ و برای AVE مقدار ۵/۰ است و مقادیری که محاسبه میشوند کاملا به بزرگی و کوچکی بارهای عاملی بستگی دارند و هر چه بارهای عاملی بزرگتری داشته باشیم پایایی ترکیبی و AVE بزرگتری داریم.
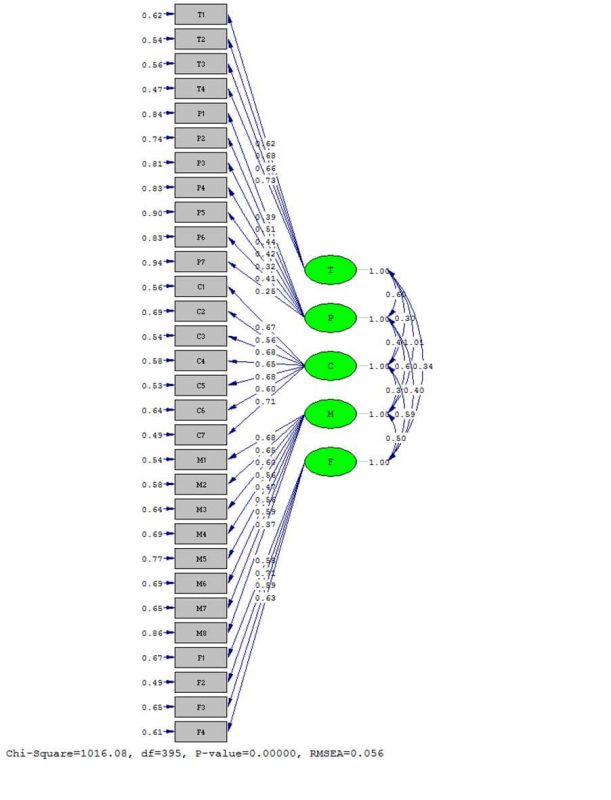
نمودار ضرایب استاندارد:
نمودار ضرایب معنیداری:
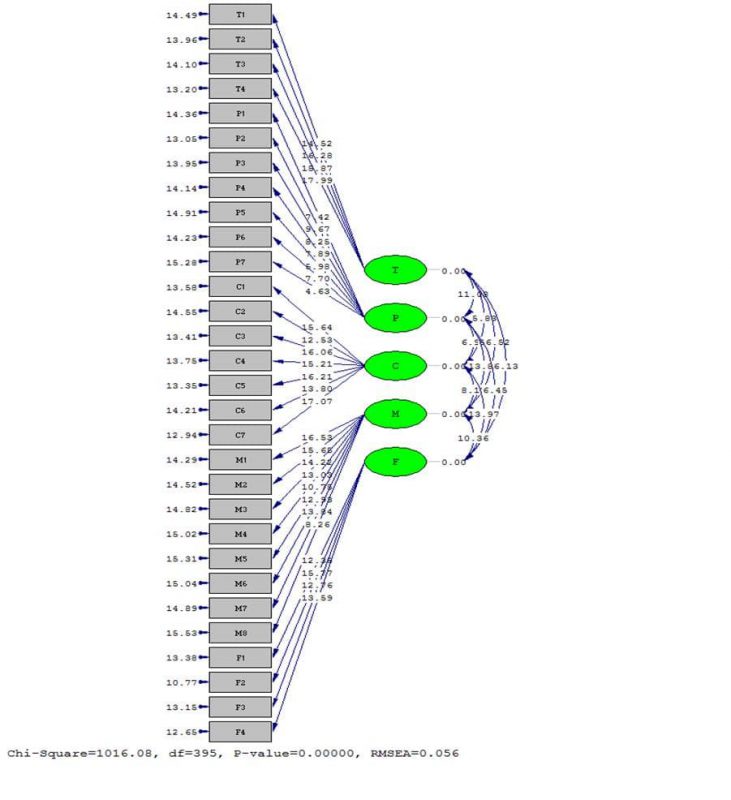
بعد از اینکه از مناسب بودن بارهای عاملی، پایایی و روایی سازه اطمینان حاصل شد به سراغ تحلیل عاملی مرتبه دوم میرویم تا عوامل موثر بر متغیر اصلی عدم گرایش به بیمه عمر را شناسایی و اولویتبندی کنیم. با توجه به اینکه T-Value متغیرهای آسیبهای فنی، شخصیتی، فرهنگی، بازاریابی و فروش و مالی بیمه عمر بزرگتر از ۹۶/۱ است بنابراین این متغیرها از عوامل موثر بر عدم گرایش به بیمه عمر به شمار میروند.
نمودار ضرایب استاندارد:
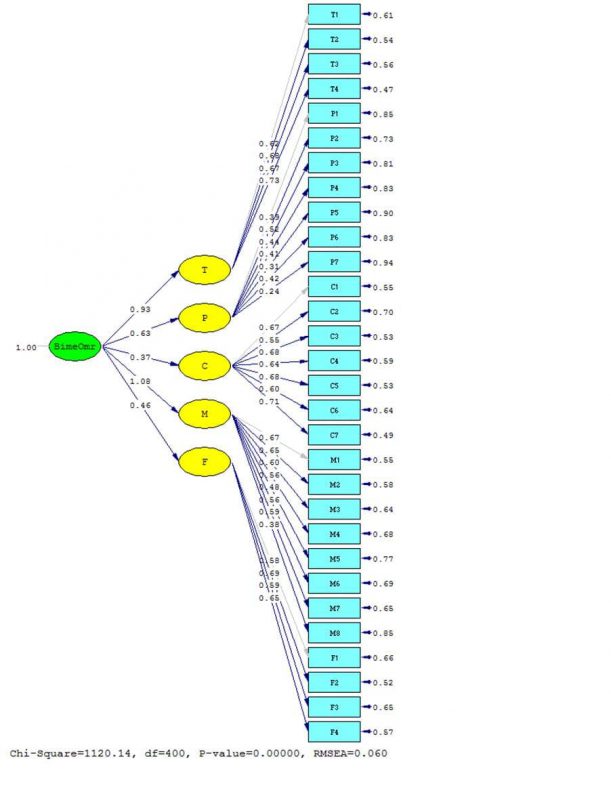
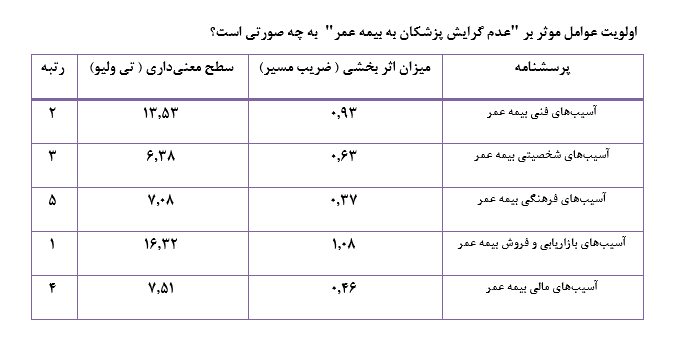
و در انتها با استفاده از ضرایب استاندارد مسیر عوامل موثر بر عدم گرایش به بیمه عمر پزشکان را اولویتبندی کردهاند. با توجه به جدول فوق در بین عوامل موثر بر “عدم گرایش پزشکان به بیمه عمر” اولویت اول مربوط به “آسیبهای بازاریابی و فروش بیمه عمر” و اولویت آخر مربوط به “آسیبهای فرهنگی بیمه عمر” میباشد.
نمونه فصل چهارم پایان نامه به شما کمک می کند تا انواع مختلف روش های آماری در عمل مشاهده کنید و بتوانید بهتر پروژه خود را انجام دهید. برای دریافت اطلاعات بیشتر درباره اشتباهات رایج در فصل چهارم پایان نامه صفحه اینستاگرام آمار پیشرو را دنبال کنید.چنانچه در مسیر انجام پروژه به مشکل خوردید می توانید در زیر همین پست مطرح کنید و چنانچه نیاز به مشاوره آماری دارید می توان از مشاوره آماری رایگان استفاده کنید.
اگر به دنبال سپردن پروژه به متخصصین و افراد با تجربه هستید می توانید در قسمت ثبت سفارش فرم را تکمیل کرده و منتظر تماس کارشناسان مربوطه باشید.

دیدگاه
جابر,
22 مه 2021سلام در مورد نرم افزار اسمارت پی ال اس میشه توضیح بدید؟چطور باید نتایج تحلیل عاملی مرتبه ی اول و دوم رو استخراج کرد؟یا یک نمونه برام میفرستید؟
لادن عباس نیا,
26 مه 2021با سلام و احترام
خیلی خوشحالیم که آمار پیشرو رو انتخاب کردین. درخصوص تحلیل آماری با نرم افزار pls مقاله کاملی در حال آماده سازی هست که به زودی در سایت منتشر میشه اما اگر عجله دارید و نمونه کار نیاز دارید به شماره ۰۹۰۲۹۹۳۶۵۰۰ در واتس اپ پیام بدین.
روح انگيز جلالي,
28 ژوئن 2021سلام من نیاز به توضیح و مشاوره برای فصل ۴ پایان نامم دارم . تحلیل داده ها با روش سلسله مراتبی فازی انجام شده و برای ارائه تسلط ندارم . ممنون میشم راهنمایی بفرمایید.
لادن,
13 جولای 2021با سلام و احترام
برای آموزش میتونید فرم ثبت سفارش رو تکمیل کنید یا در واتس اپ به شماره ۰۹۰۲۹۹۳۶۵۰۰ پیام بدین تا تحلیلتون رو از طریق اسکایپ بهتون آموزش بدیم.
مسعود,
06 جولای 2021سلام وقت بخیر
ببخشید چطور میدونم خروجی spss را به فارسی تبدیل کنم
لطفاً راهنمایی بفرمائید
مسعود,
08 جولای 2021سلام وقت بخیر
چطور میشه از خروجیspss را به فارسی تبدیل کرد
لطفاً راهنمایی بفرمائید
لادن,
13 جولای 2021با سلام و احترام
در صفحه ورود داده اطلاعات رو به صورت فارسی وارد کنید.