
هم خطی اندیکاتورها
- نویسنده : لادن عباس نیا
- ارسال شده در: دسامبر 9, 2025
- ارسال دیدگاه: ۰
در یک مدل اندازهگیری تکوینی، اگر شاخصها با یکدیگر همبستگی بالایی داشته باشند، ممکن است مشکل هم خطی نشانگر رخ دهد. همانطور که قبلا در مقاله بحث شد، رگرسیون چندگانه در SPSS می تواند برای تولید مقادیر VIF و Tolerance برای بررسی هم خطی استفاده شود. شاخص های تکوینی یک متغیر پنهان به عنوان متغیر مستقل و شاخص متغیر پنهان دیگری به عنوان متغیر وابسته تنظیم می شود.
در پنجره Statistics.” “، “Estimates”، “Model Fit” و “Colinearity diagnostics” را علامت بزنید. پس از اجرای رگرسیون خطی، جدول “ضرایب” را در خروجی SPSS پیدا کنید. فقط مقادیر تحمل و VIF نشان داده شده در ستون “آمار هم خطی” برای این تحلیل هم خطی مورد نیاز است.
ساخت مدل درونی نرم افزار SmartPLS
بر اساس چارچوب مفهومی که قبلا در این مقاله طراحی شده است، یک مدل داخلی را می توان به راحتی در SmartPLS با کلیک بر روی پنجره مدل سازی در سمت راست و سپس انتخاب دومین رنگ آبی آخر ایجاد کرد. نماد دایره ای با عنوان “Switch to Insertion Mode” را در پنجره کلیک کنید تا دایره های قرمز رنگی که متغیرهای پنهان شما را نشان می دهند ایجاد شوند. پس از قرار دادن دایره ها، روی هر متغیر پنهان کلیک راست کنید تا نام پیش فرض را به نام متغیر مناسب در مدل خود تغییر دهید. آخرین نماد با عنوان “Switch to Connection Mode” را فشار دهید تا فلش ها را برای اتصال متغیرها به یکدیگر بکشید.
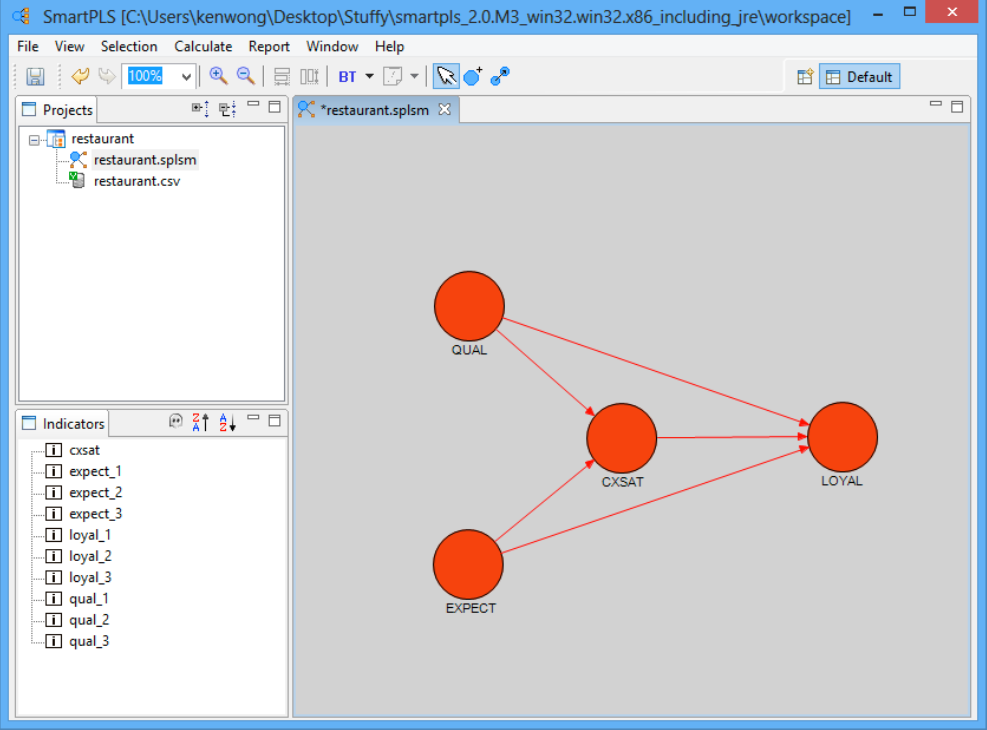
ساخت مدل بیرونی نرم افزار SmartPLS
مرحله بعدی ساخت مدل بیرونی نرم افزار SmartPLS است. برای انجام این کار، نشانگرها را با کشیدن یک به یک از زبانه «Indicators» به دایره قرمز مربوطه به متغیر پنهان مرتبط کنید. هر نشانگر با یک مستطیل زرد نشان داده می شود و رنگ متغیر نهفته با ایجاد پیوند از قرمز به آبی تغییر می کند. اگر روی متغیر نهفته آبی رنگ راست کلیک کنید، می توان با استفاده از عملکرد “Align Top/Bottom/Left/Right” نشانگرها را بر روی صفحه نمایش جا به جا کرد.
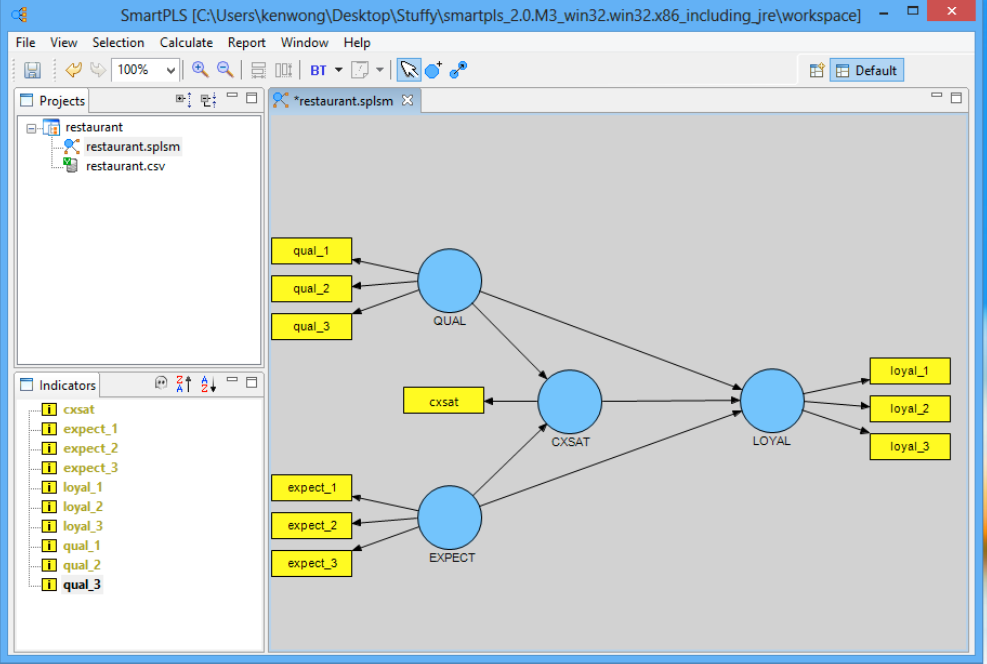
اندازه گیری شکل دهنده در مقابل انعکاس
دو نوع مقیاس اندازه گیری در مدل سازی معادلات ساختاری وجود دارد. می تواند شکل دهنده یا بازتابی باشد.
مقیاس اندازه گیری شکل دهنده
اگر شاخص ها باعث ایجاد متغیر پنهان شوند و بین خودشان قابل تعویض نباشند، شکل دهنده هستند. به طور کلی، این شاخص های شکلدهنده میتوانند همبستگی مثبت، منفی یا حتی بدون همبستگی بین یکدیگر داشته باشند (Haenlein & Kaplan, 2004; Petter et al., 2007). به این ترتیب، در صورت استفاده از مقیاس اندازه گیری تکوینی، نیازی به گزارش پایایی شاخص، پایایی همسانی درونی و اعتبار متمایز وجود ندارد. این موضوع به این دلیل است که بارهای بیرونی، قابلیت اطمینان مرکب و جذر میانگین واریانس استخراج شده (AVE) برای یک متغیر پنهان که از معیارهای نامرتبط تشکیل شده است، بی معنی هستند.
یک مثال خوب از مقیاس اندازه گیری تکوینی، اندازه گیری سطح استرس کارکنان است. از آنجایی که این یک متغیر پنهان است که اغلب اندازه گیری مستقیم آن دشوار است، محققان باید به شاخص هایی مانند طلاق، از دست دادن شغل و تصادف رانندگی که می توانند اندازه گیری شوند، توجه کنند. در اینجا بدیهی است که تصادف رانندگی لزوما ربطی به طلاق یا از دست دادن شغل ندارد و این شاخص ها قابل تعویض نیستند.
هنگامی که شاخص های شکل دهنده در مدل وجود دارد، جهت فلش ها باید معکوس شود. یعنی فلش باید از نشانگرهای شکل دهنده زرد به متغیر پنهان آبی رنگ در نرم افزار SmartPLS اشاره کند. این را می توان به راحتی با کلیک راست بر روی متغیر پنهان و انتخاب “مدل اندازه گیری معکوس” برای تغییر جهت پیکان انجام داد.
مقیاس اندازه گیری بازتابی
اگر شاخص ها بسیار همبسته و قابل تعویض باشند، بازتابی می شوند و پایایی و اعتبار آنها باید به طور کامل مورد بررسی قرار می گیرد (Haenlein & Kaplan, 2004; Hair et al., 2013; Petter et al., 2007). به عنوان مثال، متغیر نهفته کیفیت درک شده (QUAL) در مجموعه داده های رستوران ما از سه شاخص مشاهده شده تشکیل شده است: طعم غذا، حرفه ای بودن سرور و دقت صورتحساب. بارگذاری بیرونی، قابلیت اطمینان ترکیبی، AVE و ریشه مربع آن باید بررسی و گزارش شود.
در مقیاس اندازه گیری بازتابی، جهت علیت از متغیر پنهان آبی رنگ به شاخص های زرد رنگ می رود. توجه به این نکته مهم است که به طور پیشفرض، نرم افزار SmartPLS فرض میکند که شاخصها در هنگام ساخت مدل منعکسکننده هستند، با فلشهایی که به سمت متغیر پنهان آبی رنگ قرار دارند. یکی از اشتباهات رایجی که محققان در هنگام استفاده از نرم افزار SmartPLS مرتکب میشوند این است که فراموش میکنند جهت فلشها را زمانی که شاخصها بهجای «بازتابی» «تشکیلدهنده» هستند، تغییر دهند. از آنجایی که همه نشانگرهای این نمونه رستوران منعکس کننده هستند، نیازی به تغییر جهت فلش نیست.
ما به بررسی این مثال بازتابی ادامه خواهیم داد و هنگامی که تجزیه و تحلیل SmartPLS انجام شد، بحث در مورد یک مدل اندازهگیری تکوینی دنبال خواهد شد.
اجرای تخمین مدل سازی مسیر
هنگامی که نشانگرها و متغیرهای نهفته با موفقیت در نرم افزار SmartPLS به یکدیگر مرتبط شدند (یعنی دیگر دایره و فلش قرمز رنگی وجود ندارد)، با رفتن به منوی «محاسبه» و انتخاب «الگوریتم PLS»، میتوان روش مدلسازی مسیر را انجام داد. اگر منو کم رنگ است، کافیست روی پنجره اصلی مدلسازی کلیک کنید تا فعال شود. یک پنجره پاپ آپ برای نمایش تنظیمات پیش فرض نمایش داده می شود. از آنجایی که هیچ مقدار از دست رفته ۱۸ برای مجموعه داده های ما وجود ندارد، ما مستقیما به نیمه پایینی پنجره پاپ آپ می رویم تا “الگوریتم PLS – تنظیمات” را با پارامترهای زیر پیکربندی کنیم :
- طرح وزن: طرح وزن دهی مسیر
- داده متریک: میانگین ۰، واریانس ۱
- حداکثر تکرار: ۳۰۰
- معیار سقط: ۱.0E-5
- وزن اولیه: ۱.۰
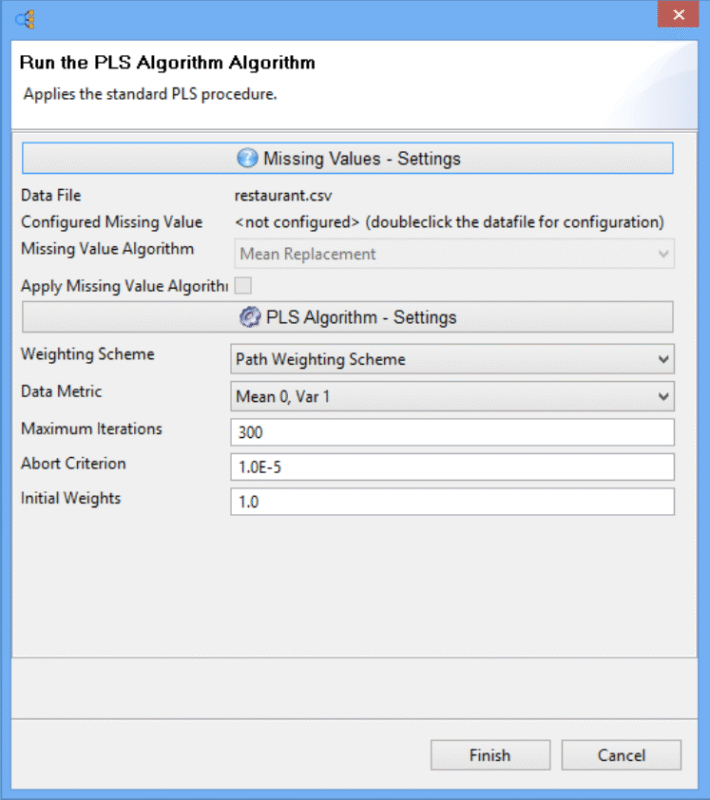
برای اجرای مدلسازی مسیر، دکمه «پایان» را فشار دهید. هیچ پیغام خطایی نباید روی صفحه ظاهر شود، و اکنون می توان نتیجه را ارزیابی و گزارش کرد.
ارزیابی خروجی نرم افزار SmartPLS
SmartPLS تخمینهای مدلسازی مسیر را نه تنها در پنجره مدلسازی، بلکه در یک گزارش مبتنی بر متن ارائه میکند که از طریق منوی «گزارش» قابل دسترسی است. در نمودار PLS-SEM دو نوع اعداد وجود دارد:
- اعداد در دایره: این اعداد نشان می دهد که چقدر واریانس متغیر پنهان توسط سایر متغیرهای پنهان توضیح داده می شود.
- اعداد روی فلش: به آنها ضرایب مسیر می گویند. آنها توضیح می دهند که تأثیر یک متغیر بر متغیر دیگر چقدر قوی است. وزن ضرایب مسیر مختلف ما را قادر می سازد تا اهمیت آماری نسبی آنها را رتبه بندی کنیم.
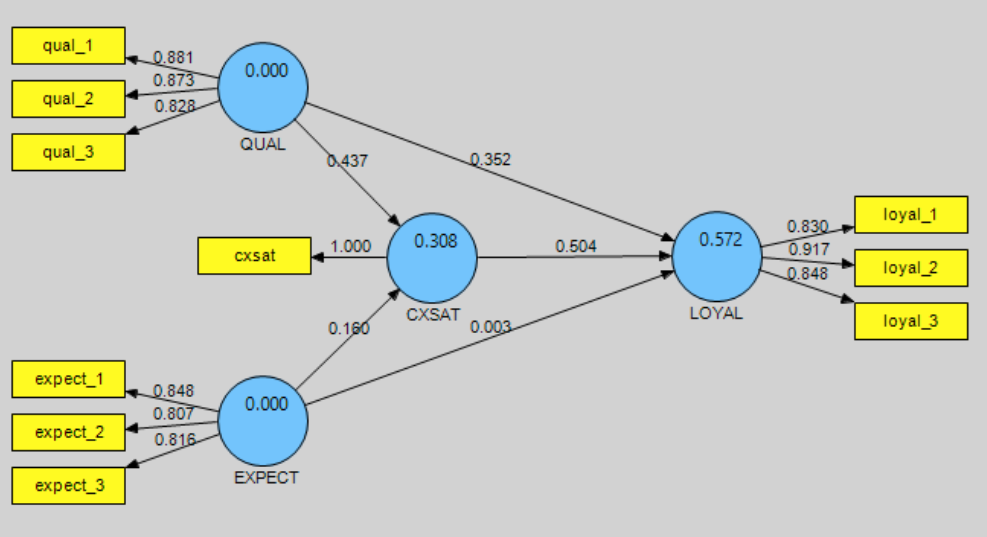
حال میتوانیم مشاهدات اولیه زیر را انجام دهیم:
توضیح واریانس متغیر درون زای هدف
ضریب تعیین، R2، ۰.۵۷۲ برای متغیر نهفته درون زا LOYAL است. این بدان معناست که سه متغیر پنهان (QUAL، EXPECT و CXSAT) به طور متوسط ۲۳/۵۷ درصد از واریانس LOYAL را توضیح می دهند.
QUAL (کیفیت ) و EXPECT (پیش بینی ) با هم ۳۰.۸ درصد از واریانس CXSAT.24 را توضیح می دهند.
اندازه و اهمیت ضریب مسیر مدل داخلی
مدل درونی نشان میدهد که CXSAT قویترین اثر را بر روی( LOYAL (0.504 دارد و پس از آن( QUAL (0.352 و ( EXPECT (0.003 قرار دارند.
ارتباط مسیر فرضی بین QUAL و LOYAL (وفادار) از نظر آماری معنادار است.
ارتباط مسیر فرضی بین CXSAT و LOYAL از نظر آماری معنادار است.
اما رابطه مسیر فرضی بین EXPECT و LOYAL از نظر آماری معنادار نیست. این به این دلیل است که ضریب مسیر استاندارد شده آن (۰.۰۰۳) کمتر از ۰.۱ است. بنابراین میتوان نتیجه گرفت که: CXSAT و QUAL (کیفیت) هر دو پیشبینیکننده نسبتا قوی LOYAL (وفادار)هستند، اما EXPECT (پیش بینی ) مستقیما LOYAL را پیشبینی نمیکند.
بارگذاری مدل بیرونی
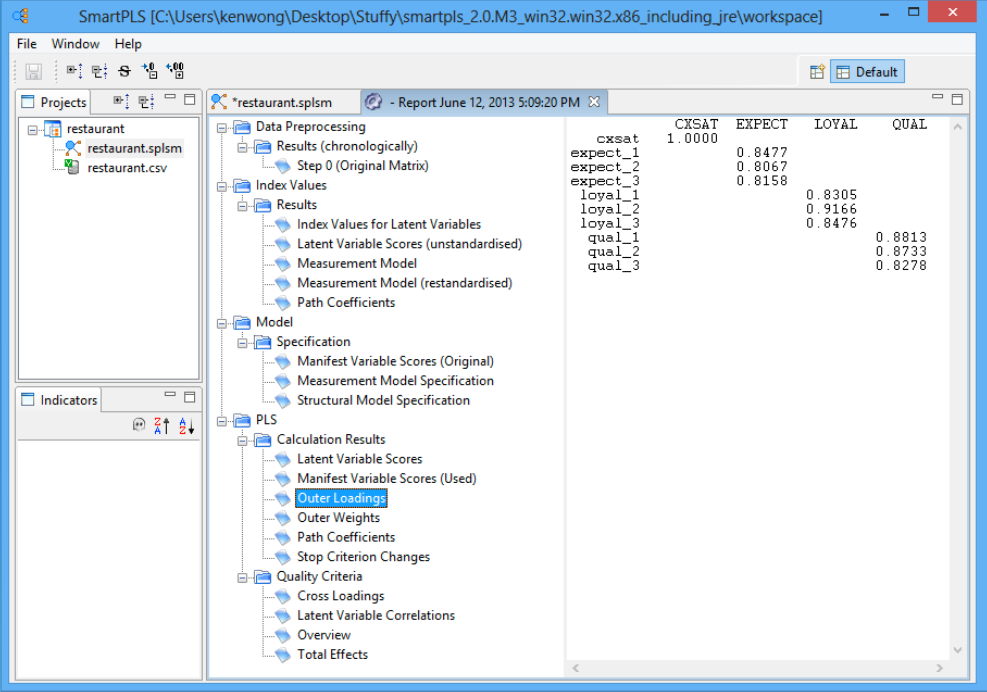
برای مشاهده همبستگی بین متغیر پنهان و نشانگرهای مدل بیرونی آن، در منو به «گزارش» بروید و «گزارش پیشفرض» را انتخاب کنید. از آنجایی که ما یک مدل بازتابی در این مثال رستوران داریم، به اعدادی که در پنجره “بارگیری های خارجی” نشان داده شده است نگاه می کنیم (PLS → نتایج محاسبه→ بارگیری های بیرونی). ما میتوانیم نماد «Toggle Zero Values» را فشار دهیم تا صفرهای اضافی جدول را برای مشاهده آسانتر ضرایب مسیر حذف کنیم .
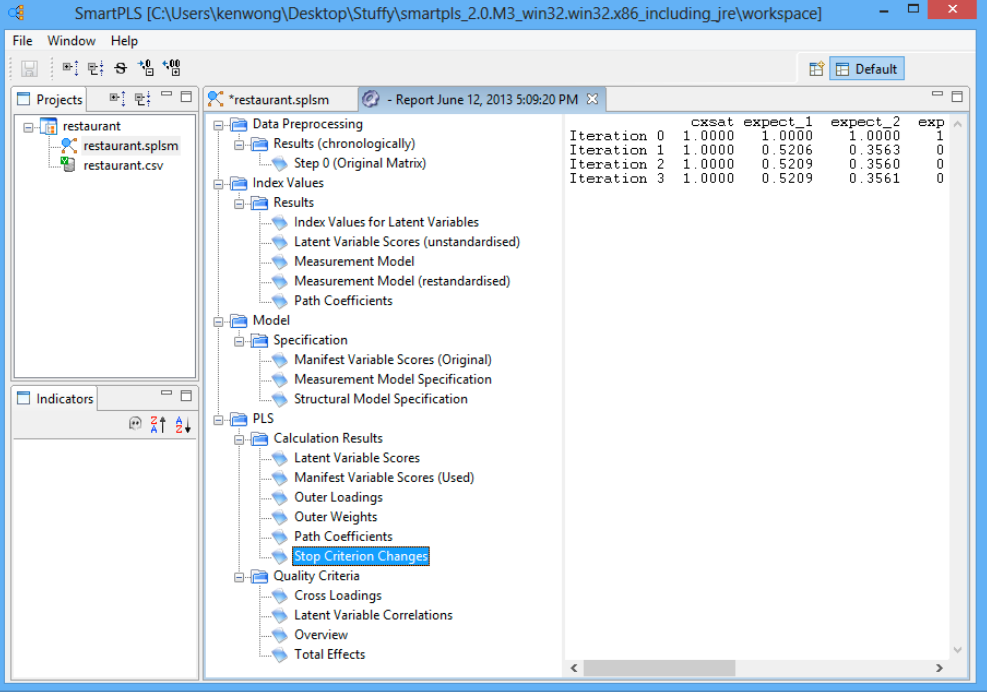
در SmartPLS، نرم افزار تخمین را زمانی متوقف می کند که (۱) معیار توقف الگوریتم به دست آید، یا (۲ ) به حداکثر تعداد تکرارها رسیده باشد، هر کدام که زودتر اتفاق بیفتد. از آنجایی که قصد داریم یک تخمین پایدار به دست آوریم، می خواهیم الگوریتم قبل از رسیدن به حداکثر تعداد تکرارها همگرا شود. برای دیدن اینکه آیا چنین است، به “توقف تغییرات معیار” بروید تا تعیین کنید که چند تکرار انجام شده است. در این مثال رستوران، الگوریتم تنها پس از ۴ تکرار (به جای رسیدن به ۳۰۰) همگرا شد، بنابراین تخمین ما خوب است.
قابلیت اطمینان نشانگر
درست مانند سایر تحقیقات بازاریابی، برای تکمیل بررسی مدل ساختاری، تعیین پایایی و اعتبار متغیرهای پنهان ضروری است.
اولین موردی که باید بررسی شود «قابلیت اطمینان شاخص» است .مشاهده می شود که همه شاخص ها دارای مقادیر پایایی شاخص فردی هستند که بسیار بزرگتر از حداقل سطح قابل قبول ۰.۴ و نزدیک به سطح ترجیحی ۰.۷ است.
قابلیت اطمینان سازگاری داخلی
به طور سنتی، “آلفای کرونباخ” برای اندازه گیری قابلیت اطمینان درونی در تحقیقات علوم اجتماعی استفاده می شود، اما تمایل به ارائه یک اندازه گیری محافظه کارانه در SmartPLS دارد. ادبیات قبلی استفاده از «پایایی ترکیبی» را به عنوان جایگزین پیشنهاد کرده است (باکوزی و یی، ۱۹۸۸؛ هیر و همکاران، ۲۰۱۲). بنابراین سطوح بالایی از قابلیت اطمینان سازگاری داخلی در بین هر سه متغیر پنهان بازتابنده نشان داده شده است.
اعتبار همگرا
برای بررسی اعتبار همگرا، میانگین واریانس استخراج شده هر متغیر پنهان (AVE) ارزیابی می شود. مشخص می شود که همه مقادیر AVE بزرگتر از آستانه قابل قبول ۰.۵ هستند، بنابراین اعتبار همگرا تأیید می شود.
اعتبار متمایز
فورنل و لارکر (۱۹۸۱) پیشنهاد میکنند که ریشه دوم AVE در هر متغیر پنهان میتواند برای ایجاد اعتبار متمایز استفاده شود، اگر این مقدار بزرگتر از سایر مقادیر همبستگی در بین متغیرهای پنهان باشد. برای این کار جدولی ایجاد می شود که در آن جذر AVE به صورت دستی محاسبه شده و در مورب جدول به صورت پررنگ نوشته می شود. همبستگی بین متغیرهای پنهان از بخش “همبستگی متغیر پنهان” گزارش پیش فرض کپی شده و در مثلث پایین سمت چپ جدول قرار می گیرد .
به عنوان مثال، متغیر پنهان EXPECT sAVE برابر با ۰.۶۷۸۳ است، بنابراین ریشه دوم آن ۰.۸۲۴ می شود. این عدد بزرگتر از مقادیر همبستگی در ستون( EXPECT (0.446 و ۰.۴۵۸ و همچنین بزرگتر از مقادیر موجود در ردیف( EXPECT (0.655 است. مشاهدات مشابهی نیز برای متغیرهای نهفته QUAL، CXSAT و LOYAL انجام شده است. نتایج نشان میدهد که اعتبار متمایز به خوبی تثبیت شده است.
بررسی اهمیت مسیر ساختاری در بوت استرپینگ
نرم افزار SmartPLS می تواند آمار T را برای آزمایش اهمیت هر دو مدل داخلی و خارجی، با استفاده از روشی به نام bootstrapping تولید کند. در این روش، تعداد زیادی از نمونههای فرعی (مثلاً ۵۰۰۰) از نمونه اصلی با جایگزینی گرفته میشود تا خطاهای استاندارد بوت استرپ را نشان دهد، که به نوبه خود مقادیر T تقریبی را برای آزمایش اهمیت مسیر ساختاری به دست میدهد. نتیجه Bootstrap به طور تقریبی نرمال بودن داده ها را نشان می دهد.
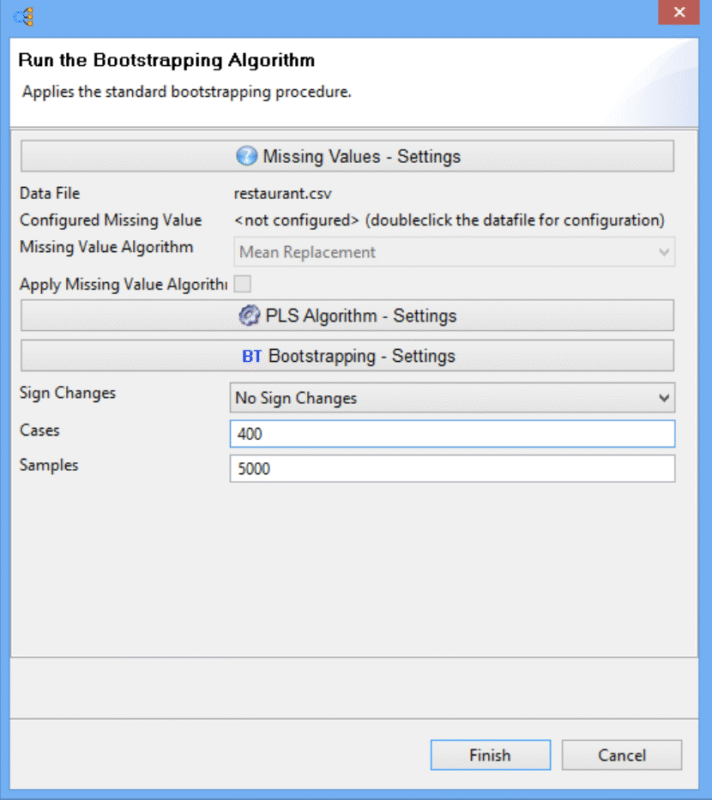
برای انجام این کار، به منوی “Calculate” رفته و “Bootstrapping” را انتخاب کنید. در SmartPLS، اندازه نمونه به عنوان Cases در زمینه Bootstrapping شناخته می شود، در حالی که تعداد زیر نمونه های بوت استرپ به عنوان Samples (نمونه ها ) شناخته می شود. از آنجایی که ۴۰۰ مشاهده معتبر ۳۱ در مجموعه دادههای رستوران ما وجود دارد، تعداد موارد (بدون نمونه ها) در تنظیمات باید به ۴۰۰ مورد افزایش یابد، و سایر پارامترها بدون تغییر باقی میمانند:
- تغییر علامت: بدون تغییر علامت
- موارد: ۴۰۰
- نمونه: ۵۰۰۰
شایان ذکر است که اگر نتیجه بوت استرپینگ با استفاده از گزینه “بدون تغییر علامت” ناچیز باشد، اما با استفاده از گزینه “تغییر علائم فردی” نتیجه معکوس حاصل شود، پس از آن باید با استفاده از “سطح ساخت و ساز” وسط، این روش را دوباره اجرا کنید. گزینه Changes و به جای آن از آن نتیجه استفاده کنید. این به این دلیل است که این گزینه به عنوان یک سازش خوب بین دو تنظیمات تغییر علامت شدید شناخته شده است.
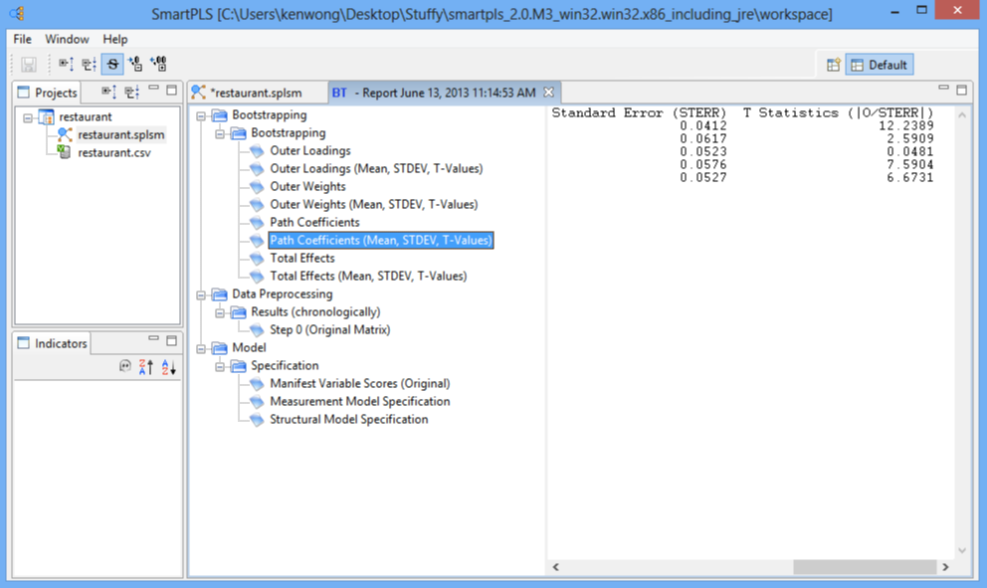
پس از تکمیل فرآیند راهاندازی، به پنجره «ضرایب مسیر (میانگین، STDEV، T-Values) که در بخش Bootstrapping در گزارش پیشفرض قرار دارد، بروید. اعداد موجود در ستون “T-Statistics” را بررسی کنید تا ببینید آیا ضرایب مسیر مدل داخلی قابل توجه است یا خیر. با استفاده از آزمون t دو طرفه با سطح معنی داری ۵ درصد، ضریب مسیر در صورتی معنی دار خواهد بود که آماره T32 بزرگتر از ۱.۹۶ باشد. در مثال رستوران ما، مشاهده می شود که فقط پیوند (EXPECT – LOYAL” (0.0481 معنی دار نیست. این یافتههای قبلی ما را هنگام مشاهده بصری نتایج PLS-SEM تأیید میکند . تمام ضرایب مسیر دیگر در مدل داخلی از نظر آماری معنادار هستند .
پس از بررسی ضریب مسیر برای مدل داخلی، میتوانیم مدل خارجی را با بررسی آمار T در پنجره «بارگذاریهای خارجی (میانگین، STDEV، T-Values)» بررسی کنیم. همه آمار T بزرگتر از ۱.۹۶ هستند، بنابراین می توان گفت که بارگذاری مدل بیرونی بسیار قابل توجه است. همه این نتایج یک تجزیه و تحلیل اساسی از نرم افزار SmartPLS در مثال رستوران ما را تکمیل می کند.
ملاحظات دیگر هنگام انجام تحلیل عمیق نرم افزار SmartPLS
عمق تجزیه و تحلیل SmartPLS به محدوده پروژه تحقیقاتی، پیچیدگی مدل، و ارائه رایج در ادبیات قبلی بستگی دارد. به عنوان مثال، تجزیه و تحلیل دقیق PLS-SEM اغلب شامل ارزیابی چند خطی می شود. یعنی هر مجموعه ای از متغیرهای پنهان بیرونی در مدل داخلی برای مشکل هم خطی بالقوه بررسی می شود تا ببینیم آیا هر متغیری باید حذف شود، در یکی ادغام شود یا به سادگی یک متغیر پنهان مرتبه بالاتر توسعه داده شود.
برای ارزیابی مسائل همخطی مدل داخلی، نمرات متغیر پنهان (PLS →نتایج محاسبه →امتیازهای متغیر پنهان) را می توان به عنوان ورودی برای رگرسیون چندگانه در IBM SPSS Statistics برای بدست آوردن مقادیر تحمل یا واریانس ضریب تورم (VIF) استفاده کرد. زیرا نرم افزار SmartPLS این اعداد را ارائه نمی دهد. ابتدا مطمئن شوید که مجموعه داده ها با فرمت فایل csv. هستند. سپس داده ها را به SPSS وارد کرده و به Analyze → Regression →Linear بروید. در ماژول رگرسیون خطی SPSS، متغیرهای پنهان برون زا (پیش بینی کننده ها) به عنوان متغیرهای مستقل پیکربندی می شوند، در حالی که متغیر پنهان دیگری (که به عنوان یک پیش بینی عمل نمی کند) به عنوان متغیر وابسته پیکربندی می شود. VIF به عنوان “۱/تحمل” محاسبه می شود. به عنوان یک قاعده کلی، ما باید یک VIF 5 یا کمتر (یعنی سطح تحمل ۰.۲ یا بالاتر) داشته باشیم تا از مشکل هم خطی اجتناب کنیم (Hair et al., 2011).
علاوه بر بررسی هم خطی بودن، می توان بحث مفصلی در مورد اندازه اثر f2 مدل داشت که نشان می دهد یک متغیر نهفته برون زا چقدر به مقدار R2 یک متغیر پنهان درون زا کمک می کند. به عبارت ساده، اندازه اثر، بزرگی یا قدرت رابطه بین متغیرهای پنهان را ارزیابی می کند. چنین بحثی می تواند مهم باشد زیرا اندازه اثر به محققان کمک می کند تا سهم کلی یک مطالعه تحقیقاتی را ارزیابی کنند. چین، مارکولین و نیوستد (۱۹۹۶) به وضوح اشاره کرده اند که محقق نه تنها باید نشان دهد که آیا رابطه بین متغیرها معنادار است یا خیر، بلکه باید اندازه اثر بین این متغیرها را نیز گزارش کند.
در همین حال، ارتباط پیشبینیکننده جنبه دیگری است که برای مدل درونی قابل بررسی است. مقادیر Stone-Geisser (Q2) (یعنی معیارهای افزونگی اعتبار متقابل) را می توان با روش Blindfoldingدر نرم افزارSmartPLS (محاسبه → Blindfolding) به دست آورد. در پنجره تنظیمات Blindfolding، فاصله حذف (OD) 5 تا ۱۰ برای اکثر تحقیقات پیشنهاد شده است (Hair et al., 2012). اندازه اثر q2 برای مقادیر Q2 نیز قابل محاسبه و بحث است.
اگر یک متغیر نهفته واسطه در مدل وجود داشته باشد، میتوان اثر کل یک متغیر پنهان برونزای خاص را بر متغیر پنهان درونزا نیز مورد بحث قرار داد. مقدار اثر کل را می توان در گزارش پیش فرض پیدا کرد (PLS →معیارهای کیفیت →اثرات کل). اهمیت اثر کل را می توان با استفاده از T-Statistics در روش بوت استرپینگ (Bootstrapping Total Effects (میانگین، STDEV، T-Values)) آزمایش کرد.
همچنین، ناهمگونی مشاهده نشده ممکن است زمانی که اطلاعات کمی در مورد داده های اساسی وجود دارد، ارزیابی شود، زیرا ممکن است بر اعتبار تخمین نرم افزار SmartPLS تأثیر بگذارد.

دیدگاه بگذارید